冠军方案之 宫颈癌风险智能诊断
freeopen 2021-02-14 [机器学习] #top1赛道1冠军:deep-thinker 团队
赛道2冠军:LLLLC 队
任务说明
通过提供大规模经过专业医师标注的宫颈癌液基薄层细胞检测数据,选手能够提出并综合运用目标检测、深度学习等方法对宫颈癌细胞学异常鳞状上皮细胞进行定位以及对宫颈癌细胞学图片分类,提高模型检测的速度和精度,辅助医生进行诊断。
宫颈癌细胞学图片采用kfb格式,每张数据在20倍数字扫描仪下获取,大小300~400M。
初赛环节
宫颈癌细胞学图片800张,其中阳性图片500张,阴性图片300张。阳性图片会提供多个ROI区域,在ROI区域里面标注异常鳞状上皮细胞位置,阴性图片不包含异常鳞状上皮细胞,无标注。初赛讨论的异常鳞状上皮细胞主要包括四类:ASC-US(非典型鳞状细胞不能明确意义),LSIL(上皮内低度病变),ASC-H(非典型鳞状细胞倾向上皮细胞内高度),HSIL(上皮内高度病变)。(特别注明:阳性图片ROI区域之外不保证没有异常鳞状上皮细胞)
复赛环节
通过线上赛的方式,不允许选手下载数据,在线完成模型训练。
复赛训练集共提供1690张数据,其中1440张包含标注,250张没有标注。1440张有标注数据在ROI区域内标注了6类异常细胞,分别是阳性类别“ASC-H”、“ASC-US”、“HSIL”、“LSIL”,和阴性类别“Candida”、“Trichomonas”。250张没有标注数据表示未见上皮内细胞病变(NILM,可以理解为整图中不含任何前述六类细胞)。复赛测试集提供350张数据,给出ROI区域内6类异常细胞的位置、类别和概率。
标注数据
一张宫颈癌细胞学图片kfb文件和对应一个标注json文件。标注json文件内容是一个list文件,里面记录了每个ROI区域的位置和异常鳞状上皮细胞的位置坐标(细胞所在矩形框的左上角坐标和矩形宽高)。类别roi表示感兴趣区域,pos表示异常鳞状上皮细胞。json标注文件示例如下:
[{"x": 33842, "y": 31905, "w": 101, "h": 106, "class": "pos"},
{"x": 31755, "y": 31016, "w": 4728, "h": 3696, "class": "roi"},
{"x": 32770, "y": 34121, "w": 84, "h": 71, "class": "pos"},
{"x": 13991, "y": 38929, "w": 131, "h": 115, "class": "pos"},
{"x": 9598, "y": 35063, "w": 5247, "h": 5407, "class": "roi"},
{"x": 25030, "y": 40115, "w": 250, "h": 173, "class": "pos"}]
赛道一: 算法赛道
用常规机器学习算法得出结果。
赛道二: VNNI模型量化
由于病理图像输入尺寸非常大,通常可以达到几G几十亿个像素,传统的NvidiaGPU无法容纳更多的全局图像信息,并且低效的推理过程。本次大赛将由intel支持,参赛者可以摆脱GPU显存限制,验证intel VNNI在超高分辨率病理图像上的工程效率。
评估指标
采用目标检测任务常用的mAP(mean Average Precision)指标作为本次宫颈癌肿瘤细胞检测的评测指标。我们采用两个IoU阈值(0.3,0.5)分别来计算AP,再综合平均作为最终的评测结果。
赛道二的评价指标,mAP@0.5 和 QPS,即精度和速度
数据分析
- 数据集目标尺度差异较大,最大最小可相差将近十万倍。比如,大目标面积可达5500x4000像素,小的只有10x10像素。因此,要求模型具有较好的多尺度检测能力。
- 目标宽高比主要集中在0.5~2的区间,但仍存在一定数量的极端目标。因此,将增加anchor设计难度,也较为依赖特定的先验知识。
- 图像尺寸非常大,背景复杂。
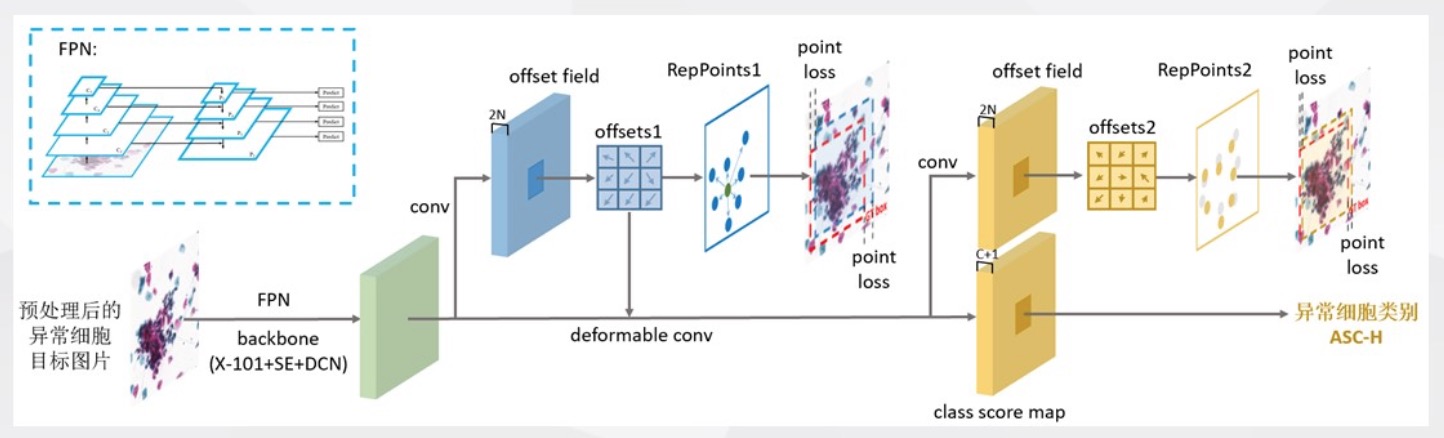
赛道一方案
没有采用常用的anchor-based模型,而是选择了非常契合本次赛题特点的anchor-free模型RepPoints。
RepPoints(ResNeXt101 + FPN + SE + DCN)
在线随机裁剪
随机选择输入图片中的一个目标,围绕目标随机切出边长在768~2048范围内的子图,然后缩放至边长为1024后,再送进网络。若目标边长超过了范围,则将目标与少量背景直接切出,再进行缩放。
RepPoints 模型
- 核心: 物体表示上采用点集来替代传统边界框
- 边界框只提供粗糙定位,而RepPoints可自适应地分布于物体重要的局部语义区域,可提供更加细致的几何描述,有利于目标特征提取
- 采用中心点代替anchor作为初始时目标表示方式,相比传统Anchor机制,中心点更易覆盖定位二维的假设空间,无须依赖尺度和宽高比设置
- 其他各点可由中心点加上预测的偏移量计算得到,并自适应地分布于目标重要语义区域
- 为了利用仍为边界框的标注,训练时将点集转为边界框,从而计算目标定位的损失
- 对比其他anchor-free模型,不需要额外监督,自顶向下
- 通过两次预测偏移量,对目标表示中各点位置进行优化,最终获得精确定位
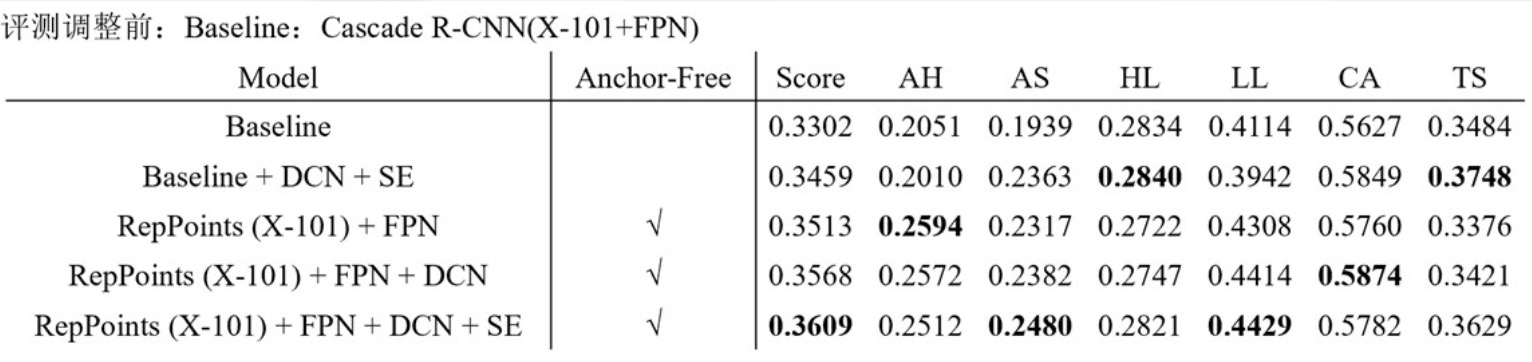
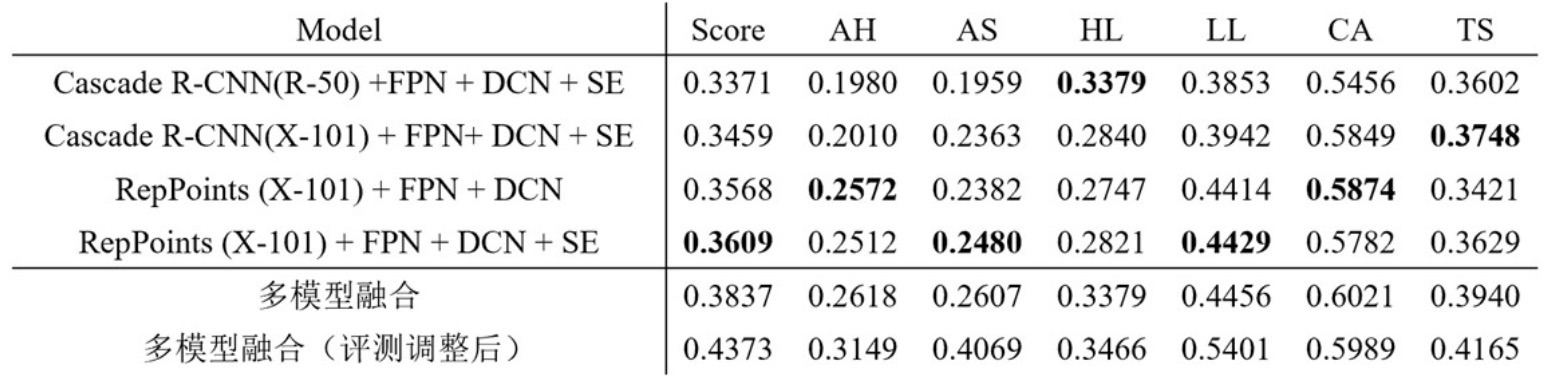
实验结果及模型融合
赛道二方案
数据增强
- 从ROI中“在线”随机裁剪 (Online crop)
- 随机翻转(Random flip)
- 移动标注框(Shift GT),采用cv2.inpaint进行填补

- 背景替换(Replace BG),利用阴性图片作物背景,并染色剂归一化

整体架构
基于OpenVINO的量化推理架构

模型结构:
主模型为RetinaNet , 用开源的 imageNet 预训练模型初始化。
比较两种类型的backbone:
- Res50-FPN256-Head256
- MbV2-FPN128-Head64, 相较于上面的Res50 约12倍加速
模型训练
训练策略
超参数:
- 学习率:余弦下降,初始学习率0.01, 终止学习率为0.00001
- Batch size: 8
- 预训练模型: ImageNet,训练时不固定BN参数
- Epoch: 100
裁剪策略:
从ROI中裁剪1600 x 1600,在缩小到 800 x 800,这样可以增加标注框的数量,提高训练效率,在推理时也可以减少滑窗数量。
量化策略
OpenVINO的量化工具,该工具的后两个步骤是将一些INT8层切换回FP32,用于提升acc,实验中发现这两个步骤对我们的模型不起作用,精度损失仍然很大。通过经验化的方法,我们发现FPN部分对量化比较敏感,因此在量化时不对FPN部分进行量化。
校验选择300张训练图片,除FPN部分的卷积层外,其余卷积层全部量化。
模型推理
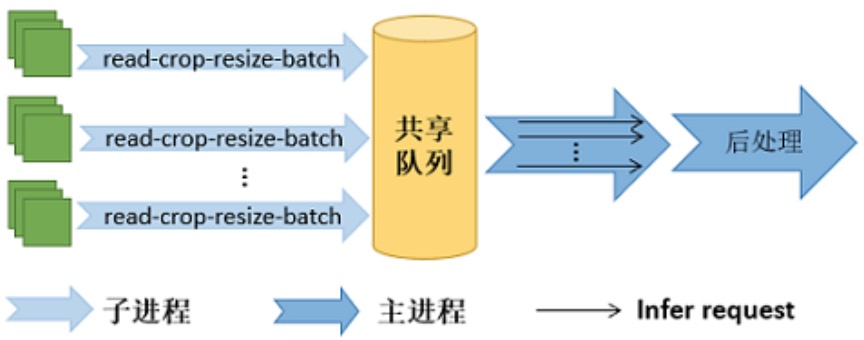
图片读取及预处理
- 图片读取部分我们采用了GDAL库,发现跟OpenCV相比有接近2倍的性能提升。
- 多个子进程同时读取图片,存放到共享队列中。
- 丢弃边界像素
- 裁剪1600x1600缩小到800x800
- 无重叠滑窗
前向执行
采用OpenVINO的异步模式
- 发起执行请求好,控制权交还回主程序,分摊数据读取和后处理的时间。其中子进程负责图片的读取、裁剪、缩放、拼batch 等数据操作,处理完的数据存放到共享队列中;
- 执行完成后,通过回调函数通知主程序。主进程从共享队列读取数据,负责模型推理、后处理操作。(使用 “生产者-消费者”模式,采用共享队列实现数据的通信)
- 可并发多个 infer request
实验结果
map0.5: 33.54%, 推理总时长:24s。