冠军方案之铝型材表面瑕疵识别
freeopen 2021-02-13 [机器学习] #top1冠军:Are you OK 战队(中山大学曾兆阳等)
任务说明
在铝型材的实际生产过程中,由于各方面因素的影响,铝型材表面会产生裂纹、起皮、划伤等瑕疵,这些瑕疵会严重影响铝型材的质量。铝型材的表面自身会含有纹路,与瑕疵的区分度不高。传统人工肉眼检查十分费力,不能及时准确的判断出表面瑕疵,质检的效率难以把控。铝型材制造商迫切希望采用最新的AI技术来革新现有质检流程,自动完成质检任务,减少漏检发生率,提高产品的质量,使铝型材产品的生产管理者彻底摆脱了无法全面掌握产品表面质量的状态。
初赛数据量3000张图片,复赛数据量5000张图片,包含单瑕疵图片,多瑕疵图片,无瑕疵图片,用于参赛者设计图像识别算法。图片所含瑕疵类型总计10种,分别为:不导电、擦花、角位漏底、桔皮、漏底、喷流、漆泡、起坑、杂色、脏点。
评价指标
参照2010年之后PASCALVOC的评估标准,检测框和真实框的交并比(IOU)阈值设定为0.5,同时,采用Interpolating all points方法插值获得PR曲线,并在此基础上计算mAP的值,计算10类瑕疵的mAP值作为赛手的分数。
本次大赛计算mAP时,对同一个ground-truth框,重复预测n次,取置信度(confidence)最高的预测框作为TP(true positive)样本,其余的n-1个框都作为FP(False positive)样本进行处理。
数据分析
从数据中可以看到,
脏点的占比面积特别小,喷流与背景很相似,擦花很不规则。- 大部分的类别是十分均衡的,
脏点这个类的数量较多。缺陷框的大小两级分化 比较严重。在这其中,小样本的缺陷框基本上都是脏点的类别 - 原始图片的分辨率非常的大,是1920*2560
模型设计
基本架构采用Faster R-CNN, backbone选取Resnet-101。
原图输入=>下采样2倍=>Resnet-101(下采样16倍),也就是说,从原图到最后一层的卷积特征,空间大小一共下降了32倍($60\cdot80$)。 由于之后每一个候选框特征会被缩放到 $7\cdot7$ 的大小,如果说本身缩放前的特征就非常的小,那么缩放之后的特征是 不具有判别力的。统计了一下数据集中边长 <=64 的样本,发现这类小样本占了整个数据集的10%,这会严重地影响性能。
改进方案
特征金字塔
为了解决这个问题,我们采用了学术界非常常用的特征金字塔结构来对网络进行改进。我们总结了一下,特征金字 塔在这个任务中具有两个优点:第一,低层的特征经过卷积,上采样操作之后和高层的信息进行融合在卷积神经网络中,高层,也就是后面的特征具有强的语义信息,低层的特征具有结构信息,因此将高低层的信息进行结合,是可以增强特征的表达能力的。第二,我们将候选框产生和提取特征的位置分散到了特征金字塔的每一层,这样可以增加小目标的特征映射分辨率,对最后的预测也是有好处的。
可变形卷积
我们采用的第二个改进方案是Deformable Convolutoin可变形卷积。我们发现在数据集中,铝材的瑕疵有很多是这种条状的,传统正规的正方形结构的卷积对这种形状的缺陷处理能力还不够强。因此我们采用了可变形的卷积, 在卷积计算的过程中能够自动地计算每个点的偏移,从而从最合适的地方取特征进行卷积。右边的示意图大致描述 了可变形卷积的过程,它能够让卷积的区域尽可能地集中在缺陷上。
具体实现上,将原本resent结构的最后一个block改成了可变卷积,原因是在可变卷积的实现中,需要基于前面 的特征来学习一个偏移,前面的特征得足够强才能保证这个偏移不会乱学,因此我们只改动了最后一个block。总体 的框架还是跟前面FPN的一样。
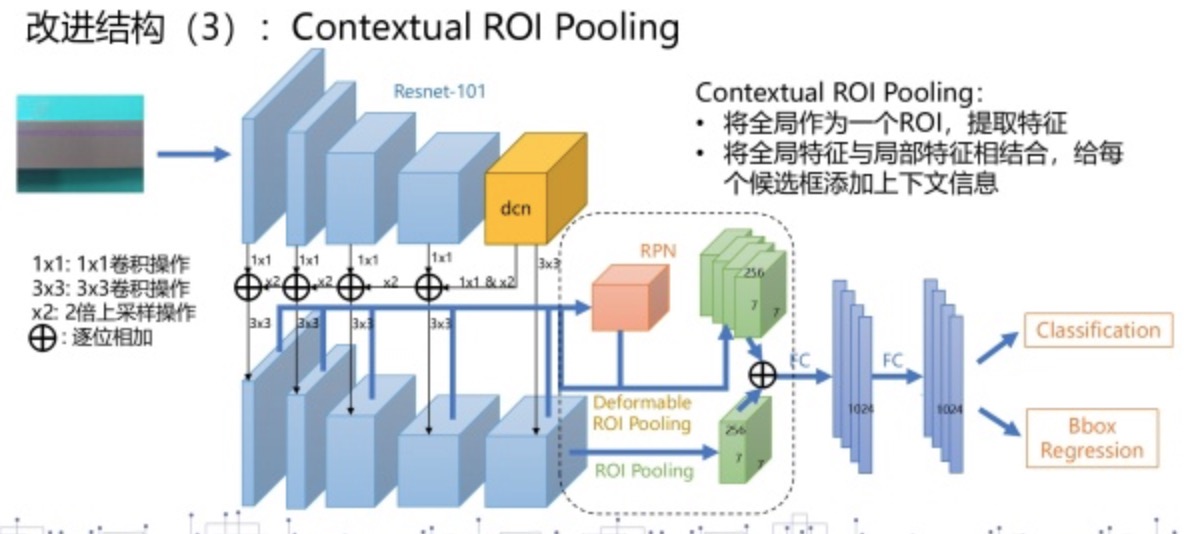
Contextual ROI Pooling

我们的第三个改进方案,是在提取ROI特征的时候,引入了context上下文信息,我们把这个操作叫做contextual roi pooling。我们用上面两个例子来说明上下文信息的好处。Faster R-CNN是一个先生成候选框,然后精调候选框的过程,那么第一步生成的候选框势必会有偏大或者偏小的情况。之前的方法可以理解成用框内部的信息来推断框的 位置,左边这个例子是框偏大的情况,根据内部信息是可以知道框应该往里调的,但是右边这个例子框偏小了, 我们能知道该往外调整,但是该调多少呢这个是无从知晓的。因此一个显而易见的想法,就是把整张图片的信息也 送给这个候选框当特征,这样相当于让每个候选框以整张图片作为参考,这样呢每个框就知道该往哪调了。
具体的实现是这样,我们把整张图片也作为一个roi,用同样的ROI Pooling提取全局的特征,然后跟每一个候选框 的特征相加,再进行后面的分类和回归操作。这样的实现只多进行了一个roi的特征提取和一个特征相加的操作, 却能大大地提升准确率。
训练技巧
数据集里面是有提供无缺陷样本的,我们也对这些图片进行了使用。 在检测器的训练过程中,有一步是正负样本的选择。我们在训练的时候使用了一个策略,每次会随机选择一张缺陷样本和一张无缺陷样本,然后训练的正样本会在缺陷图片中选择,负样本会在两张图片中都选择,两张图片的所有 正负样本合起来做一个OHEM(Online hard example mining),再进行后面的训练操作。这样的好处是,充分利用了无缺陷样本,增大了模型判别背景信息的能力。
铝材的缺陷是具有翻转不变性的,将一张图片水平和竖直翻转之后,他的瑕疵信 息是不会变的,也就是说,我们将图片进行翻转之后,再将框做一个变换到对应的位置,这样可以构建出一批新的数据来。通过这样的数据扩增方式,我们把训练数据扩增了四倍,也因此提升了模型的鲁棒性。
实验结果研究
通过分析实验和结果,我们发现擦花和喷流差的原因是基本都是召回率较低。在生成检测结果的时候,用了softnms来提高模型分数。softnms的作用是在框之间互 相抑制的时候使用了较温和的策略,让被抑制过的框还有机会重新被选上,从而提高召回率。从实验结果可以看到,softnms在每个类上都有提升。