机器学习术语表
freeopen 2018-02-26 [速查手册] #ml为方便读论文时查询术语,只做英文目录,我会不时把新遇到的术语增补到这里。 初版来自 Google Developers 网站。 有不准确的地方请来信告知,我会即时更正。
本术语表定义了一般机器学习术语以及特定于 TensorFlow 的术语。
常用评价指标导航
A
A/B testing
A statistical way of comparing two (or more) techniques, typically an incumbent against a new rival. A/B testing aims to determine not only which technique performs better but also to understand whether the difference is statistically significant. A/B testing usually considers only two techniques using one measurement, but it can be applied to any finite number of techniques and measures.
一种统计方法,用于将两种或多种技术进行比较,通常是将当前采用的技术与新技术进行比较。A/B 测试不仅旨在确定哪种技术的效果更好,而且还有助于了解相应差异是否具有显著的统计意义。A/B 测试通常是采用一种衡量方式对两种技术进行比较,但也适用于任意有限数量的技术和衡量方式。
accuracy
The fraction of predictions that a classification model got right. In multi-class classification, accuracy is defined as follows:
In binary classification, accuracy has the following definition:
See true positive) and true negative.
分类模型的正确预测所占的比例。在多类别分类中,准确率的定义如下:
在二元分类中,准确率的定义如下:
activation function
A function (for example, ReLU or sigmoid) that takes in the weighted sum of all of the inputs from the previous layer and then generates and passes an output value (typically nonlinear) to the next layer.
一种函数(例如 ReLU 或 S 型函数),用于对上一层的所有输入求加权和,然后生成一个输出值(通常为非线性值),并将其传递给下一层。
AdaGrad
A sophisticated gradient descent algorithm that rescales the gradients of each parameter, effectively giving each parameter an independent learning rate. For a full explanation, see this paper.
一种先进的梯度下降法,用于重新调整每个参数的梯度,以便有效地为每个参数指定独立的学习速率。如需查看完整的解释,请参阅这篇论文。
AP
平均精度,衡量在单个类别上的平均精度, 所有类别上的平均精度称为平均精度均值mAP。以2010年为界,前后有两种算法。
第一种算法,首先设定一组recall阈值,[0, 0.1, 0.2, …, 1]。然后对每个查全率或召回率recall阈值从小到大取值,同时计算当取大于该recall阈值时top-n所对应的最大查准率precision。这样,我们就计算出了11个precision。AP 即为这 11 个 precision 的平均值。这种方法英文叫做 11-point interpolated average precision。
第二种算法,假设 N 个样本中有 M 个正例,那么我们会得到 M 个recall值(1/M, 2/M, …, M/M),对于每个 recall 值 r,该recall阈值时top-n所对应的最大precision,然后对这 M 个 precision 值取平均即得到最后的AP值。
AUC (Area under the ROC Curve)
An evaluation metric that considers all possible classification thresholds.
The Area Under the ROC curve is the probability that a classifier will be more confident that a randomly chosen positive example is actually positive than that a randomly chosen negative example is positive.
一种会考虑所有可能分类阈值的评估指标。
ROC 曲线下面积是,对于随机选择的正类别样本确实为正类别,以及随机选择的负类别样本为正类别,分类器更确信前者的概率。
B
backpropagation
The primary algorithm for performing gradient descent on neural networks. First, the output values of each node are calculated (and cached) in a forward pass. Then, the partial derivative of the error with respect to each parameter is calculated in a backward pass through the graph.
在神经网络上执行梯度下降法的主要算法。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
baseline
A simple model or heuristic used as reference point for comparing how well a model is performing. A baseline helps model developers quantify the minimal, expected performance on a particular problem.
一种简单的模型或启发法,用作比较模型效果时的参考点。基准有助于模型开发者针对特定问题量化最低预期效果。
batch
The set of examples used in one iteration (that is, one gradient update) of model training.
See also batch size.
另请参阅批次规模。
batch size
The number of examples in a batch. For example, the batch size of SGD is 1, while the batch size of a mini-batch is usually between 10 and 1000. Batch size is usually fixed during training and inference; however, TensorFlow does permit dynamic batch sizes.
一个批次中的样本数。例如,SGD 的批次规模为 1,而小批次的规模通常介于 10 到 1000 之间。批次规模在训练和推断期间通常是固定的;不过,TensorFlow 允许使用动态批次规模。
bias
An intercept or offset from an origin. Bias (also known as the bias term) is referred to as $b$ or $w_0$ in machine learning models. For example, bias is the b in the following formula:
距离原点的截距或偏移。偏差(也称为偏差项)在机器学习模型中以 $b$ 或 $w_0$ 表示。例如,在下面的公式中,偏差为 b:
$$y’ = b + w_1x_1 + w_2x_2 + … w_nx_n$$
Not to be confused with prediction bias.
请勿与预测偏差混淆。
binary classification
A type of classification task that outputs one of two mutually exclusive classes. For example, a machine learning model that evaluates email messages and outputs either “spam” or “not spam” is a binary classifier.
一种分类任务,可输出两种互斥类别之一。例如,对电子邮件进行评估并输出“垃圾邮件”或“非垃圾邮件”的机器学习模型就是一个二元分类器。
binning
See bucketing.
BLEU
BLEU( bilingual evaluation understudy ) 双语评估替换, 是一种文本评估算法,它是用来评估机器翻译跟专业人工翻译之间的对应关系,核心思想就是机器翻译越接近专业人工翻译,质量就越好,经过bleu算法得出的分数可以作为机器翻译质量的其中一个指标。
整个算法的公式较复杂,列示如下:
$$BLEU = BP\cdot exp(\sum_{n=1}^N w_n\log p_n) \tag{1}$$
$$p_n = {\sum_{C\in {Candidates}} \sum_{\text{n-gram} \in C} Count_{clip}(\text{n-gram}) \over \sum_{C^{‘}\in {Candidates}} \sum_{\text{n-gram}^{’} \in C^{‘}} Count(\text{n-gram}^{’}) } \tag{2}$$
$$ BP=\begin{cases} 1, & \text{if $c > r$} \\ e^{(1-r/c)}, & \text {if $c \leq r$} \end{cases} $$
$$Count_{clip} = min(Count, Max_Ref_Count) \tag{4}$$
其中,(1)式为总公式,(2)(3)式是对(1)式的说明,(4)式是对(2)式的说明。
- (2)式称为N-gram(注:N 的取值范围通常为1至4)距离计算公式,在评测机器翻译任务时,用机器译文去对比参考译文, 分子部分表示取n-gram在机器译文和参考译文中出现的最小次数, 分母部分表示取n-gram在机器译文中出现次数。
- (3)式称为惩罚因子,c是机器译文的词数,r是参考译文的词数。
- (4)式的意思是取机器译文N-gram的出现次数和参考译文中N-gram最大出现次数中的最小值, 它是对原始N-gram算法统计匹配次数的修正。
优点:方便、快速,结果比较接近人类评分。
缺点:
- 不考虑语言表达(语法)上的准确性;
- 测评精度会受常用词的干扰;
- 短译句的测评精度有时会较高;
- 没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定;
BLEU本身就不追求百分之百的准确性,也不可能做到百分之百,它的目标只是给出一个快且不差的自动评估解决方案。
bucketing
Converting a (usually continuous) feature into multiple binary features called buckets or bins, typically based on value range. For example, instead of representing temperature as a single continuous floating-point feature, you could chop ranges of temperatures into discrete bins. Given temperature data sensitive to a tenth of a degree, all temperatures between 0.0 and 15.0 degrees could be put into one bin, 15.1 to 30.0 degrees could be a second bin, and 30.1 to 50.0 degrees could be a third bin.
将一个特征(通常是连续特征)转换成多个二元特征(称为桶或箱),通常是根据值区间进行转换。例如,您可以将温度区间分割为离散分箱,而不是将温度表示成单个连续的浮点特征。假设温度数据可精确到小数点后一位,则可以将介于 0.0 到 15.0 度之间的所有温度都归入一个分箱,将介于 15.1 到 30.0 度之间的所有温度归入第二个分箱,并将介于 30.1 到 50.0 度之间的所有温度归入第三个分箱。
C
calibration layer
A post-prediction adjustment, typically to account for prediction bias. The adjusted predictions and probabilities should match the distribution of an observed set of labels.
一种预测后调整,通常是为了降低预测偏差。调整后的预测和概率应与观察到的标签集的分布一致。
candidate sampling
A training-time optimization in which a probability is calculated for all the positive labels, using, for example, softmax, but only for a random sample of negative labels. For example, if we have an example labeled beagle and dog candidate sampling computes the predicted probabilities and corresponding loss terms for the beagle and dog class outputs in addition to a random subset of the remaining classes (cat, lollipop, fence). The idea is that the negative classes can learn from less frequent negative reinforcement as long as positive classes always get proper positive reinforcement, and this is indeed observed empirically. The motivation for candidate sampling is a computational efficiency win from not computing predictions for all negatives.
一种训练时进行的优化,会使用某种函数(例如 softmax)针对所有正类别标签计算概率,但对于负类别标签,则仅针对其随机样本计算概率。例如,如果某个样本的标签为“小猎犬”和“狗”,则候选采样将针对“小猎犬”和“狗”类别输出以及其他类别(猫、棒棒糖、栅栏)的随机子集计算预测概率和相应的损失项。这种采样基于的想法是,只要正类别始终得到适当的正增强,负类别就可以从频率较低的负增强中进行学习,这确实是在实际中观察到的情况。候选采样的目的是,通过不针对所有负类别计算预测结果来提高计算效率。
categorical data
Features having a discrete set of possible values. For example, consider a categorical feature named house style, which has a discrete set of three possible values: Tudor, ranch, colonial. By representing house style as categorical data, the model can learn the separate impacts of Tudor, ranch, and colonial on house price.
Sometimes, values in the discrete set are mutually exclusive, and only one value can be applied to a given example. For example, a car maker categorical feature would probably permit only a single value (Toyota) per example. Other times, more than one value may be applicable. A single car could be painted more than one different color, so a car color categorical feature would likely permit a single example to have multiple values (for example, red and white).
Categorical features are sometimes called discrete features.
Contrast with numerical data.
一种特征,拥有一组离散的可能值。以某个名为 house style 的分类特征为例,该特征拥有一组离散的可能值(共三个),即 Tudor, ranch, colonial。通过将 house style 表示成分类数据,相应模型可以学习 Tudor、ranch 和 colonial 分别对房价的影响。
有时,离散集中的值是互斥的,只能将其中一个值应用于指定样本。例如,car maker 分类特征可能只允许一个样本有一个值 (Toyota)。在其他情况下,则可以应用多个值。一辆车可能会被喷涂多种不同的颜色,因此,car color 分类特征可能会允许单个样本具有多个值(例如 red 和 white)。
分类特征有时称为离散特征。
与数值数据相对。
checkpoint
Data that captures the state of the variables of a model at a particular time. Checkpoints enable exporting model weights, as well as performing training across multiple sessions. Checkpoints also enable training to continue past errors (for example, job preemption). Note that the graph itself is not included in a checkpoint.
一种数据,用于捕获模型变量在特定时间的状态。借助检查点,可以导出模型权重,跨多个会话执行训练,以及使训练在发生错误之后得以继续(例如作业抢占)。请注意,图本身不包含在检查点中。
class
One of a set of enumerated target values for a label. For example, in a binary classification model that detects spam, the two classes are spam and not spam. In a multi-class classification model that identifies dog breeds, the classes would be poodle, beagle, pug, and so on.
为标签枚举的一组目标值中的一个。例如,在检测垃圾邮件的二元分类模型中,两种类别分别是“垃圾邮件”和“非垃圾邮件”。在识别狗品种的多类别分类模型中,类别可以是“贵宾犬”、“小猎犬”、“哈巴犬”等等。
class-imbalanced data set
A binary classification problem in which the labels for the two classes have significantly different frequencies. For example, a disease data set in which 0.0001 of examples have positive labels and 0.9999 have negative labels is a class-imbalanced problem, but a football game predictor in which 0.51 of examples label one team winning and 0.49 label the other team winning is not a class-imbalanced problem.
在二元分类问题问题中,两种类别的标签在出现频率方面具有很大的差距。例如,在某个疾病数据集中,0.0001 的样本具有正类别标签,0.9999 的样本具有负类别标签,这就属于分类不平衡问题;但在某个足球比赛预测器中,0.51 的样本的标签为其中一个球队赢,0.49 的样本的标签为另一个球队赢,这就不属于分类不平衡问题。
classification model
A type of machine learning model for distinguishing among two or more discrete classes. For example, a natural language processing classification model could determine whether an input sentence was in French, Spanish, or Italian. Compare with regression model.
一种机器学习模型,用于区分两种或多种离散类别。例如,某个自然语言处理分类模型可以确定输入的句子是法语、西班牙语还是意大利语。请与回归模型进行比较。
classification threshold
A scalar-value criterion that is applied to a model’s predicted score in order to separate the positive class from the negative class. Used when mapping logistic regression results to binary classification. For example, consider a logistic regression model that determines the probability of a given email message being spam. If the classification threshold is 0.9, then logistic regression values above 0.9 are classified as spam and those below 0.9 are classified as not spam.
一种标量值条件,应用于模型预测的得分,旨在将正类别与负类别区分开。将逻辑回归结果映射到二元分类时使用。以某个逻辑回归模型为例,该模型用于确定指定电子邮件是垃圾邮件的概率。如果分类阈值为 0.9,那么逻辑回归值高于 0.9 的电子邮件将被归类为“垃圾邮件”,低于 0.9 的则被归类为“非垃圾邮件”。
collaborative filtering
Making predictions about the interests of one user based on the interests of many other users. Collaborative filtering is often used in recommendation systems.
根据很多其他用户的兴趣来预测某位用户的兴趣。协同过滤通常用在推荐系统中。
confusion matrix
An NxN table that summarizes how successful a classification model’s predictions were; that is, the correlation between the label and the model’s classification. One axis of a confusion matrix is the label that the model predicted, and the other axis is the actual label. N represents the number of classes. In a binary classification problem, N=2. For example, here is a sample confusion matrix for a binary classification problem:
| Systems | Tumor (predicted) | Non-Tumor (predicted) |
|---|---|---|
| Tumor (actual) | 18 | 1 |
| Non-Tumor (actual) | 6 | 452 |
The preceding confusion matrix shows that of the 19 samples that actually had tumors, the model correctly classified 18 as having tumors (18 true positives), and incorrectly classified 1 as not having a tumor (1 false negative). Similarly, of 458 samples that actually did not have tumors, 452 were correctly classified (452 true negatives) and 6 were incorrectly classified (6 false positives).
The confusion matrix for a multi-class classification problem can help you determine mistake patterns. For example, a confusion matrix could reveal that a model trained to recognize handwritten digits tends to mistakenly predict 9 instead of 4, or 1 instead of 7.
Confusion matrices contain sufficient information to calculate a variety of performance metrics, including precision and recall.
一种 NxN 表格,用于总结分类模型的预测成效;即标签和模型预测的分类之间的关联。在混淆矩阵中,一个轴表示模型预测的标签,另一个轴表示实际标签。N 表示类别个数。在二元分类问题中,N=2。例如,下面显示了一个二元分类问题的混淆矩阵示例:
| Systems | 肿瘤(预测) | 非肿瘤(预测) |
|---|---|---|
| 肿瘤 (实际) | 18 | 1 |
| 非肿瘤(实际) | 6 | 452 |
上面的混淆矩阵显示,在 19 个实际有肿瘤的样本中,该模型正确地将 18 个归类为有肿瘤(18 个真正例),错误地将 1 个归类为没有肿瘤(1 个假负例)。同样,在 458 个实际没有肿瘤的样本中,模型归类正确的有 452 个(452 个真负例),归类错误的有 6 个(6 个假正例)。
多类别分类问题的混淆矩阵有助于确定出错模式。例如,某个混淆矩阵可以揭示,某个经过训练以识别手写数字的模型往往会将 4 错误地预测为 9,将 7 错误地预测为 1。
混淆矩阵包含计算各种效果指标(包括精确率和召回率)所需的充足信息。
continuous feature
A floating-point feature with an infinite range of possible values. Contrast with discrete feature.
一种浮点特征,可能值的区间不受限制。与离散特征相对。
convergence
Informally, often refers to a state reached during training in which training loss and validation loss change very little or not at all with each iteration after a certain number of iterations. In other words, a model reaches convergence when additional training on the current data will not improve the model. In deep learning, loss values sometimes stay constant or nearly so for many iterations before finally descending, temporarily producing a false sense of convergence.
See also early stopping.
See also Boyd and Vandenberghe, Convex Optimization.
通俗来说,收敛通常是指在训练期间达到的一种状态,即经过一定次数的迭代之后,训练损失和验证损失在每次迭代中的变化都非常小或根本没有变化。也就是说,如果采用当前数据进行额外的训练将无法改进模型,模型即达到收敛状态。在深度学习中,损失值有时会在最终下降之前的多次迭代中保持不变或几乎保持不变,暂时形成收敛的假象。
另请参阅早停法。
另请参阅 Boyd 和 Vandenberghe 合著的 Convex Optimization(《凸优化》)。
convex function
A function in which the region above the graph of the function is a convex set. The prototypical convex function is shaped something like the letter U. For example, the following are all convex functions:
一种函数,函数图像以上的区域为凸集。典型凸函数的形状类似于字母 U。例如,以下都是凸函数:
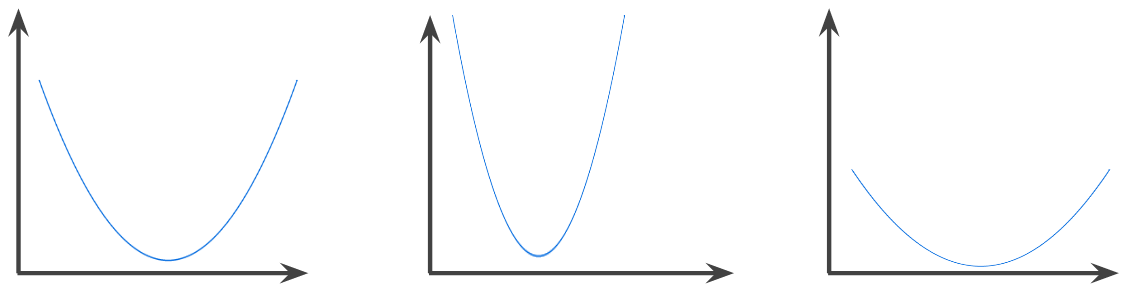
By contrast, the following function is not convex. Notice how the region above the graph is not a convex set:
相反,以下函数则不是凸函数。请注意图像上方的区域如何不是凸集:
Nonconvex function A nonconvex function that looks like a curved “W” character, with two local minimum.
非凸函数的形状类似于字母W, 有两个局部最低点.
A strictly convex function has exactly one local minimum point, which is also the global minimum point. The classic U-shaped functions are strictly convex functions. However, some convex functions (for example, straight lines) are not.
A lot of the common loss functions, including the following, are convex functions:
Many variations of gradient descent are guaranteed to find a point close to the minimum of a strictly convex function. Similarly, many variations of stochastic gradient descent have a high probability (though, not a guarantee) of finding a point close to the minimum of a strictly convex function.
The sum of two convex functions (for example, L2 loss + L1 regularization) is a convex function.
Deep models are never convex functions. Remarkably, algorithms designed for convex optimization tend to find reasonably good solutions on deep networks anyway, even though those solutions are not guaranteed to be a global minimum.
严格凸函数只有一个局部最低点,该点也是全局最低点。经典的 U 形函数都是严格凸函数。不过,有些凸函数(例如直线)则不是这样。
很多常见的损失函数(包括下列函数)都是凸函数:
梯度下降法的很多变体都一定能找到一个接近严格凸函数最小值的点。同样,随机梯度下降法的很多变体都有很高的可能性能够找到接近严格凸函数最小值的点(但并非一定能找到)。
两个凸函数的和(例如 L2 损失函数 + L1 正则化)也是凸函数。
深度模型绝不会是凸函数。值得注意的是,专门针对凸优化设计的算法往往总能在深度网络上找到非常好的解决方案,虽然这些解决方案并不一定对应于全局最小值。
convex optimization
The process of using mathematical techniques such as gradient descent to find the minimum of a convex function. A great deal of research in machine learning has focused on formulating various problems as convex optimization problems and in solving those problems more efficiently.
For complete details, see Boyd and Vandenberghe, Convex Optimization.
使用数学方法(例如梯度下降法)寻找凸函数最小值的过程。机器学习方面的大量研究都是专注于如何通过公式将各种问题表示成凸优化问题,以及如何更高效地解决这些问题。
如需完整的详细信息,请参阅 Boyd 和 Vandenberghe 合著的 Convex Optimization(《凸优化》)。
convex set
A subset of Euclidean space such that a line drawn between any two points in the subset remains completely within the subset. For instance, the following two shapes are convex sets:
欧几里德空间的一个子集,其中任意两点之间的连线仍完全落在该子集内。例如,下面的两个图形都是凸集:

By contrast, the following two shapes are not convex sets:
相反,下面的两个图形都不是凸集:

cost
Synonym for loss.
cross-entropy
A generalization of Log Loss to multi-class classification problems. Cross-entropy quantifies the difference between two probability distributions. See also perplexity.
对数损失函数向多类别分类问题进行的一种泛化。交叉熵可以量化两种概率分布之间的差异。另请参阅困惑度。
custom Estimator
An Estimator that you write yourself by following these directions.
Contrast with pre-made Estimators.
D
data set
A collection of examples.
一组样本的集合。
Dataset API (tf.data)
A high-level TensorFlow API for reading data and transforming it into a form that a machine learning algorithm requires. A tf.data.Dataset object represents a sequence of elements, in which each element contains one or more Tensors. A tf.data.Iterator object provides access to the elements of a Dataset.
For details about the Dataset API, see Importing Data in the TensorFlow Programmer’s Guide.
一种高级别的 TensorFlow API,用于读取数据并将其转换为机器学习算法所需的格式。tf.data.Dataset 对象表示一系列元素,其中每个元素都包含一个或多个张量。tf.data.Iterator 对象可获取 Dataset 中的元素。
如需详细了解 Dataset API,请参阅《TensorFlow 编程人员指南》中的导入数据。
decision boundary
The separator between classes learned by a model in a binary class or multi-class classification problems. For example, in the following image representing a binary classification problem, the decision boundary is the frontier between the orange class and the blue class:
在二元分类或多类别分类问题中,模型学到的类别之间的分界线。例如,在以下表示某个二元分类问题的图片中,决策边界是橙色类别和蓝色类别之间的分界线:

dense layer
Synonym for fully connected layer.
是全连接层的同义词。
deep model
A type of neural network containing multiple hidden layers. Deep models rely on trainable nonlinearities.
Contrast with wide model.
一种神经网络,其中包含多个隐藏层。深度模型依赖于可训练的非线性关系。
与宽度模型相对。
dense feature
A feature in which most values are non-zero, typically a Tensor of floating-point values. Contrast with sparse feature.
一种大部分数值是非零值的特征,通常是一个浮点值张量。参照稀疏特征。
derived feature
Synonym for synthetic feature.
是合成特征的同义词。
discrete feature
A feature with a finite set of possible values. For example, a feature whose values may only be animal, vegetable, or mineral is a discrete (or categorical) feature. Contrast with continuous feature.
一种特征,包含有限个可能值。例如,某个值只能是“动物”、“蔬菜”或“矿物”的特征便是一个离散特征(或分类特征)。与连续特征相对。
dropout regularization
A form of regularization useful in training neural networks. Dropout regularization works by removing a random selection of a fixed number of the units in a network layer for a single gradient step. The more units dropped out, the stronger the regularization. This is analogous to training the network to emulate an exponentially large ensemble of smaller networks. For full details, see Dropout: A Simple Way to Prevent Neural Networks from Overfitting.
一种形式的正则化,在训练神经网络方面非常有用。丢弃正则化的运作机制是,在神经网络层的一个梯度步长中移除随机选择的固定数量的单元。丢弃的单元越多,正则化效果就越强。这类似于训练神经网络以模拟较小网络的指数级规模集成学习。如需完整的详细信息,请参阅 Dropout: A Simple Way to Prevent Neural Networks from Overfitting(《丢弃:一种防止神经网络过拟合的简单方法》)。
dynamic model
A model that is trained online in a continuously updating fashion. That is, data is continuously entering the model.
一种模型,以持续更新的方式在线接受训练。也就是说,数据会源源不断地进入这种模型。
E
early stopping
A method for regularization that involves ending model training before training loss finishes decreasing. In early stopping, you end model training when the loss on a validation data set starts to increase, that is, when generalization performance worsens.
一种正则化方法,涉及在训练损失仍可以继续减少之前结束模型训练。使用早停法时,您会在基于验证数据集的损失开始增加(也就是泛化效果变差)时结束模型训练。
embeddings
A categorical feature represented as a continuous-valued feature. Typically, an embedding is a translation of a high-dimensional vector into a low-dimensional space. For example, you can represent the words in an English sentence in either of the following two ways:
- As a million-element (high-dimensional) sparse vector in which all elements are integers. Each cell in the vector represents a separate English word; the value in a cell represents the number of times that word appears in a sentence. Since a single English sentence is unlikely to contain more than 50 words, nearly every cell in the vector will contain a 0. The few cells that aren’t 0 will contain a low integer (usually 1) representing the number of times that word appeared in the sentence.
- As a several-hundred-element (low-dimensional) dense vector in which each element holds a floating-point value between 0 and 1. This is an embedding.
In TensorFlow, embeddings are trained by backpropagating loss just like any other parameter in a neural network.
一种分类特征,以连续值特征表示。通常,嵌套是指将高维度向量映射到低维度的空间。例如,您可以采用以下两种方式之一来表示英文句子中的单词:
- 表示成包含百万个元素(高维度)的稀疏向量,其中所有元素都是整数。向量中的每个单元格都表示一个单独的英文单词,单元格中的值表示相应单词在句子中出现的次数。由于单个英文句子包含的单词不太可能超过 50 个,因此向量中几乎每个单元格都包含 0。少数非 0 的单元格中将包含一个非常小的整数(通常为 1),该整数表示相应单词在句子中出现的次数。
- 表示成包含数百个元素(低维度)的密集向量,其中每个元素都包含一个介于 0 到 1 之间的浮点值。这就是一种嵌套。
在 TensorFlow 中,会按反向传播损失训练嵌套,和训练神经网络中的任何其他参数时一样。
empirical risk minimization (ERM)
Choosing the model function that minimizes loss on the training set. Contrast with structural risk minimization.
用于选择可以将基于训练集的损失降至最低的模型函数。与结构风险最小化相对。
ensemble
A merger of the predictions of multiple models. You can create an ensemble via one or more of the following:
- different initializations
- different hyperparameters
- different overall structure
Deep and wide models are a kind of ensemble.
多个模型的预测结果的并集。您可以通过以下一项或多项来创建集成学习:
- 不同的初始化
- 不同的超参数
- 不同的整体结构
深度模型和宽度模型属于一种集成学习。
epoch
A full training pass over the entire data set such that each example has been seen once. Thus, an epoch represents N/batch size training iterations, where N is the total number of examples.
在训练时,整个数据集的一次完整遍历,以便不漏掉任何一个样本。因此,一个周期表示(N/批次规模)次训练迭代,其中 N 是样本总数。
Estimator
An instance of the tf.Estimator class, which encapsulates logic that builds a TensorFlow graph and runs a TensorFlow session. You may create your own custom Estimators (as described here) or instantiate pre-made Estimators created by others.
tf.Estimator 类的一个实例,用于封装负责构建 TensorFlow 图并运行 TensorFlow 会话的逻辑。您可以创建自己的自定义 Estimator(如需相关介绍,请点击此处),也可以将其他人预创建的 Estimator 实例化。
example
One row of a data set. An example contains one or more features and possibly a label. See also labeled example and unlabeled example.
数据集的一行。一个样本包含一个或多个特征,此外还可能包含一个标签。另请参阅有标签样本和无标签样本。
F
F1 Score
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。 它同时兼顾了分类模型的准确率和召回率。 F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0。
$$F_1 = 2 \cdot {precison \cdot recall \over precison + recall}$$
除了$F_1$ 分数之外,$F_2$ 分数和 $F_{0.5}$ 分数在统计学中也得到大量的应用。其中,$F_2$ 分数中,召回率的权重高于准确率, 而 $F_{0.5}$ 分数中,准确率的权重高于召回率。因此,更一般的公式为:
$$F_\beta = (1+\beta^2) \cdot {precison \cdot recall \over \beta^2 \cdot precison + recall}$$
false negative (FN)
An example in which the model mistakenly predicted the negative class. For example, the model inferred that a particular email message was not spam (the negative class), but that email message actually was spam.
被模型错误地预测为负类别的样本。例如,模型推断出某封电子邮件不是垃圾邮件(负类别),但该电子邮件其实是垃圾邮件。
false positive (FP)
An example in which the model mistakenly predicted the positive class. For example, the model inferred that a particular email message was spam (the positive class), but that email message was actually not spam.
被模型错误地预测为正类别的样本。例如,模型推断出某封电子邮件是垃圾邮件(正类别),但该电子邮件其实不是垃圾邮件。
false positive rate (FP rate)
The x-axis in an ROC curve. The FP rate is defined as follows:
$$\text{False Positive Rate} = \frac{\text{False Positives}}{\text{False Positives} + \text{True Negatives}}$$
ROC 曲线中的 x 轴。FP 率的定义如下:
feature
An input variable used in making predictions.
在进行预测时使用的输入变量。
feature columns (FeatureColumns)
A set of related features, such as the set of all possible countries in which users might live. An example may have one or more features present in a feature column.
Feature columns in TensorFlow also encapsulate metadata such as:
- the feature’s data type
- whether a feature is fixed length or should be converted to an embedding
A feature column can contain a single feature.
“Feature column” is Google-specific terminology. A feature column is referred to as a “namespace” in the VW system (at Yahoo/Microsoft), or a field.
一组相关特征,例如用户可能居住的所有国家/地区的集合。样本的特征列中可能包含一个或多个特征。
TensorFlow 中的特征列内还封装了元数据,例如:
- 特征的数据类型
- 特征是固定长度还是应转换为嵌套
特征列可以包含单个特征。
“特征列”是 Google 专用的术语。特征列在 Yahoo/Microsoft 使用的 VW 系统中称为“命名空间”,也称为场。
feature cross
A synthetic feature formed by crossing (multiplying or taking a Cartesian product of) individual features. Feature crosses help represent nonlinear relationships.
通过将单独的特征进行组合(相乘或求笛卡尔积)而形成的合成特征。特征组合有助于表示非线性关系。
feature engineering
The process of determining which features might be useful in training a model, and then converting raw data from log files and other sources into said features. In TensorFlow, feature engineering often means converting raw log file entries to tf.Example protocol buffers. See also tf.Transform.
Feature engineering is sometimes called feature extraction.
指以下过程:确定哪些特征可能在训练模型方面非常有用,然后将日志文件及其他来源的原始数据转换为所需的特征。在 TensorFlow 中,特征工程通常是指将原始日志文件条目转换为 tf.Example proto buffer。另请参阅 tf.Transform。
特征工程有时称为特征提取。
feature set
The group of features your machine learning model trains on. For example, postal code, property size, and property condition might comprise a simple feature set for a model that predicts housing prices.
训练机器学习模型时采用的一组特征。例如,对于某个用于预测房价的模型,邮政编码、房屋面积以及房屋状况可以组成一个简单的特征集。
feature spec
Describes the information required to extract features data from the tf.Example protocol buffer. Because the tf.Example protocol buffer is just a container for data, you must specify the following:
- the data to extract (that is, the keys for the features)
- the data type (for example, float or int)
- The length (fixed or variable)
The Estimator API provides facilities for producing a feature spec from a list of FeatureColumns.
用于描述如何从 tf.Example proto buffer 提取特征数据。由于 tf.Example proto buffer 只是一个数据容器,因此您必须指定以下内容:
- 要提取的数据(即特征的键)
- 数据类型(例如 float 或 int)
- 长度(固定或可变)
Estimator API 提供了一些可用来根据给定 FeatureColumns 列表生成特征规范的工具。
full softmax
See softmax. Contrast with candidate sampling.
fully connected layer
A hidden layer in which each node is connected to every node in the subsequent hidden layer.
A fully connected layer is also known as a dense layer.
一种隐藏层,其中的每个节点均与下一个隐藏层中的每个节点相连。
全连接层又称为密集层。
G
generalization
Refers to your model’s ability to make correct predictions on new, previously unseen data as opposed to the data used to train the model.
指的是模型依据训练时采用的数据,针对以前未见过的新数据做出正确预测的能力。
generalized linear model
A generalization of least squares regression models, which are based on Gaussian noise, to other types of models based on other types of noise, such as Poisson noise or categorical noise. Examples of generalized linear models include:
- logistic regression
- multi-class regression
- least squares regression
The parameters of a generalized linear model can be found through convex optimization.
Generalized linear models exhibit the following properties:
- The average prediction of the optimal least squares regression model is equal to the average label on the training data.
- The average probability predicted by the optimal logistic regression model is equal to the average label on the training data.
The power of a generalized linear model is limited by its features. Unlike a deep model, a generalized linear model cannot “learn new features.”
最小二乘回归模型(基于高斯噪声)向其他类型的模型(基于其他类型的噪声,例如泊松噪声或分类噪声)进行的一种泛化。广义线性模型的示例包括:
- 逻辑回归
- 多类别回归
- 最小二乘回归
可以通过凸优化找到广义线性模型的参数。
广义线性模型具有以下特性:
- 最优的最小二乘回归模型的平均预测结果等于训练数据的平均标签。
- 最优的逻辑回归模型预测的平均概率等于训练数据的平均标签。
广义线性模型的功能受其特征的限制。与深度模型不同,广义线性模型无法“学习新特征”。
gradient
The vector of partial derivatives with respect to all of the independent variables. In machine learning, the gradient is the the vector of partial derivatives of the model function. The gradient points in the direction of steepest ascent.
偏导数相对于所有自变量的向量。在机器学习中,梯度是模型函数偏导数的向量。梯度指向最速上升的方向。
gradient clipping
Capping gradient values before applying them. Gradient clipping helps ensure numerical stability and prevents exploding gradients.
在应用梯度值之前先设置其上限。梯度裁剪有助于确保数值稳定性以及防止梯度爆炸。
gradient descent
A technique to minimize loss by computing the gradients of loss with respect to the model’s parameters, conditioned on training data. Informally, gradient descent iteratively adjusts parameters, gradually finding the best combination of weights and bias to minimize loss.
一种通过计算并且减小梯度将损失降至最低的技术,它以训练数据为条件,来计算损失相对于模型参数的梯度。通俗来说,梯度下降法以迭代方式调整参数,逐渐找到权重和偏差的最佳组合,从而将损失降至最低。
graph
In TensorFlow, a computation specification. Nodes in the graph represent operations. Edges are directed and represent passing the result of an operation (a Tensor) as an operand to another operation. Use TensorBoard to visualize a graph.
TensorFlow 中的一种计算规范。图中的节点表示操作。边缘具有方向,表示将某项操作的结果(一个张量)作为一个操作数传递给另一项操作。可以使用 TensorBoard 直观呈现图。
H
heuristic
A practical and nonoptimal solution to a problem, which is sufficient for making progress or for learning from.
一种非最优但实用的问题解决方案,足以用于进行改进或从中学习。
hidden layer
A synthetic layer in a neural network between the input layer (that is, the features) and the output layer (the prediction). A neural network contains one or more hidden layers.
神经网络中的合成层,介于输入层(即特征)和输出层(即预测)之间。神经网络包含一个或多个隐藏层。
hinge loss
A family of loss functions for classification designed to find the decision boundary as distant as possible from each training example, thus maximizing the margin between examples and the boundary. KSVMs use hinge loss (or a related function, such as squared hinge loss). For binary classification, the hinge loss function is defined as follows:
一系列用于分类的损失函数,旨在找到距离每个训练样本都尽可能远的决策边界,从而使样本和边界之间的裕度最大化。 KSVM 使用合页损失函数(或相关函数,例如平方合页损失函数)。对于二元分类,合页损失函数的定义如下:
$$\text{loss} = \text{max}(0, 1 - (y’ * y))$$
where y’ is the raw output of the classifier model:
其中“y’”表示分类器模型的原始输出:
$$y’ = b + w_1x_1 + w_2x_2 + … w_nx_n$$
and y is the true label, either -1 or +1.
Consequently, a plot of hinge loss vs. (y * y’) looks as follows:
“y”表示真标签,值为 -1 或 +1。
因此,合页损失与 (y * y’) 的关系图如下所示:
Hinge loss vs. (y * y’) A plot of hinge loss vs. raw classifier score shows a distinct hinge at the coordinate (1,0).
holdout data
Examples intentionally not used (“held out”) during training. The validation data set and test data set are examples of holdout data. Holdout data helps evaluate your model’s ability to generalize to data other than the data it was trained on. The loss on the holdout set provides a better estimate of the loss on an unseen data set than does the loss on the training set.
训练期间故意不使用(“维持”)的样本。验证数据集和测试数据集都属于维持数据。维持数据有助于评估模型向训练时所用数据之外的数据进行泛化的能力。与基于训练数据集的损失相比,基于维持数据集的损失有助于更好地估算基于未见过的数据集的损失。
hyperparameter
The “knobs” that you tweak during successive runs of training a model. For example, learning rate is a hyperparameter.
Contrast with parameter.
在模型训练的连续过程中,您调节的“旋钮”。例如,学习速率就是一种超参数。
与参数相对。
hyperplane
A boundary that separates a space into two subspaces. For example, a line is a hyperplane in two dimensions and a plane is a hyperplane in three dimensions. More typically in machine learning, a hyperplane is the boundary separating a high-dimensional space. Kernel Support Vector Machines use hyperplanes to separate positive classes from negative classes, often in a very high-dimensional space.
将一个空间划分为两个子空间的边界。例如,在二维空间中,直线就是一个超平面,在三维空间中,平面则是一个超平面。在机器学习中更典型的是:超平面是分隔高维度空间的边界。核支持向量机利用超平面将正类别和负类别区分开来(通常是在极高维度空间中)。
I
independently and identically distributed (i.i.d)
Data drawn from a distribution that doesn’t change, and where each value drawn doesn’t depend on values that have been drawn previously. An i.i.d. is the ideal gas of machine learning—a useful mathematical construct but almost never exactly found in the real world. For example, the distribution of visitors to a web page may be i.i.d. over a brief window of time; that is, the distribution doesn’t change during that brief window and one person’s visit is generally independent of another’s visit. However, if you expand that window of time, seasonal differences in the web page’s visitors may appear.
从不会改变的分布中提取的数据,其中提取的每个值都不依赖于之前提取的值。i.i.d. 是机器学习的理想气体 - 一种实用的数学结构,但在现实世界中几乎从未发现过。例如,某个网页的访问者在短时间内的分布可能为 i.i.d.,即分布在该短时间内没有变化,且一位用户的访问行为通常与另一位用户的访问行为无关。不过,如果将时间窗口扩大,网页访问者的分布可能呈现出季节性变化。
inference
In machine learning, often refers to the process of making predictions by applying the trained model to unlabeled examples. In statistics, inference refers to the process of fitting the parameters of a distribution conditioned on some observed data. (See the Wikipedia article on statistical inference.)
在机器学习中,推断通常指以下过程:通过将训练过的模型应用于无标签样本来做出预测。在统计学中,推断是指在某些观测数据条件下拟合分布参数的过程。(请参阅维基百科中有关统计学推断的文章。)
input function
In TensorFlow, a function that returns input data to the training, evaluation, or prediction method of an Estimator. For example, the training input function returns a batch of features and labels from the training set.
在 TensorFlow 中,用于将输入数据返回到 Estimator 的训练、评估或预测方法的函数。例如,训练输入函数用于返回训练集中的批次特征和标签。
input layer
The first layer (the one that receives the input data) in a neural network.
神经网络中的第一层(接收输入数据的层)。
instance
Synonym for example.
是样本的同义词。
interpretability
The degree to which a model’s predictions can be readily explained. Deep models are often non-interpretable; that is, a deep model’s different layers can be hard to decipher. By contrast, linear regression models and wide models are typically far more interpretable.
模型的预测可解释的难易程度。深度模型通常不可解释,也就是说,很难对深度模型的不同层进行解释。相比之下,线性回归模型和宽度模型的可解释性通常要好得多。
inter-rater agreement
A measurement of how often human raters agree when doing a task. If raters disagree, the task instructions may need to be improved. Also sometimes called inter-annotator agreement or inter-rater reliability. See also Cohen’s kappa, which is one of the most popular inter-rater agreement measurements.
一种衡量指标,用于衡量在执行某项任务时评分者达成一致的频率。如果评分者未达成一致,则可能需要改进任务说明。有时也称为注释者间一致性信度或评分者间可靠性信度。另请参阅 Cohen’s kappa(最热门的评分者间一致性信度衡量指标之一)。
IoU
IoU( Intersection over Union ), 交集并集比。

在目标检测任务中,要用矩形框标出目标物体的位置。上图绿色框是贴合目标物体的区域,红色框是预测区域,这种情况下交集确实是最大的,但是红色框并不能准确预测物体位置。因为预测区域总是试图覆盖目标物体而不是正好预测物体位置。如果我们能除以一个并集的大小,就可以规避这种问题, 公式如下:
$$IoU = {Area(B_p \bigcap B_{gt}) \over Area(B_p \bigcup B_{gt})}$$
其中, $B_p$代表预测框, $B_{gt}$代表真值框。
iteration
A single update of a model’s weights during training. An iteration consists of computing the gradients of the parameters with respect to the loss on a single batch of data.
模型的权重在训练期间的一次更新。迭代包含计算参数在单个批量数据上的梯度损失。
K
Keras
A popular Python machine learning API. Keras runs on several deep learning frameworks, including TensorFlow, where it is made available as tf.keras.
一种热门的 Python 机器学习 API。Keras 能够在多种深度学习框架上运行,其中包括 TensorFlow(在该框架上,Keras 作为 tf.keras 提供)。
Kernel Support Vector Machines (KSVMs)
A classification algorithm that seeks to maximize the margin between positive and negative classes by mapping input data vectors to a higher dimensional space. For example, consider a classification problem in which the input data set consists of a hundred features. In order to maximize the margin between positive and negative classes, KSVMs could internally map those features into a million-dimension space. KSVMs uses a loss function called hinge loss.
一种分类算法,旨在通过将输入数据向量映射到更高维度的空间,来最大化正类别和负类别之间的裕度。以某个输入数据集包含一百个特征的分类问题为例。为了最大化正类别和负类别之间的裕度,KSVM 可以在内部将这些特征映射到百万维度的空间。KSVM 使用合页损失函数。
L
L1 loss
Loss function based on the absolute value of the difference between the values that a model is predicting and the actual values of the labels. L1 loss is less sensitive to outliers than L2 loss.
一种损失函数,基于模型预测的值与标签的实际值之差的绝对值。与 L2 损失函数相比,L1 损失函数对离群值的敏感性弱一些。
L1 regularization
A type of regularization that penalizes weights in proportion to the sum of the absolute values of the weights. In models relying on sparse features, L1 regularization helps drive the weights of irrelevant or barely relevant features to exactly 0, which removes those features from the model. Contrast with L2 regularization.
一种正则化,根据权重的绝对值的总和来惩罚权重。在依赖稀疏特征的模型中,L1 正则化有助于使不相关或几乎不相关的特征的权重正好为 0,从而将这些特征从模型中移除。与 L2 正则化相对。
L2 loss
See squared loss.
请参阅平方损失函数。
L2 regularization
A type of regularization that penalizes weights in proportion to the sum of the squares of the weights. L2 regularization helps drive outlier weights (those with high positive or low negative values) closer to 0 but not quite to 0. (Contrast with L1 regularization.) L2 regularization always improves generalization in linear models.
一种正则化,根据权重的平方和来惩罚权重。L2 正则化有助于使离群值(具有较大正值或较小负值)权重接近于 0,但又不正好为 0。(与 L1 正则化相对。)在线性模型中,L2 正则化始终可以改进泛化。
label
In supervised learning, the “answer” or “result” portion of an example. Each example in a labeled data set consists of one or more features and a label. For instance, in a housing data set, the features might include the number of bedrooms, the number of bathrooms, and the age of the house, while the label might be the house’s price. in a spam detection dataset, the features might include the subject line, the sender, and the email message itself, while the label would probably be either “spam” or “not spam.”
在监督式学习中,标签指样本的“答案”或“结果”部分。有标签数据集中的每个样本都包含一个或多个特征以及一个标签。例如,在房屋数据集中,特征可以包括卧室数、卫生间数以及房龄,而标签则可以是房价。在垃圾邮件检测数据集中,特征可以包括主题行、发件人以及电子邮件本身,而标签则可以是“垃圾邮件”或“非垃圾邮件”。
labeled example
An example that contains features and a label. In supervised training, models learn from labeled examples.
包含特征和标签的样本。在监督式训练中,模型从有标签样本中进行学习。
lambda
Synonym for regularization rate.
(This is an overloaded term. Here we’re focusing on the term’s definition within regularization.)
是正则化率的同义词。
(多含义术语,我们在此关注的是该术语在正则化中的定义。)
layer
A set of neurons in a neural network that process a set of input features, or the output of those neurons.
Also, an abstraction in TensorFlow. Layers are Python functions that take Tensors and configuration options as input and produce other tensors as output. Once the necessary Tensors have been composed, the user can convert the result into an Estimator via a model function.
神经网络中的一组神经元,处理一组输入特征,或一组神经元的输出。
此外还指 TensorFlow 中的抽象层。层是 Python 函数,以张量和配置选项作为输入,然后生成其他张量作为输出。当必要的张量组合起来,用户便可以通过模型函数将结果转换为 Estimator。
Layers API (tf.layers)
A TensorFlow API for constructing a deep neural network as a composition of layers. The Layers API enables you to build different types of layers, such as:
tf.layers.Densefor a fully-connected layer.tf.layers.Conv2Dfor a convolutional layer.
When writing a custom Estimator, you compose Layers objects to define the characteristics of all the hidden layers.
The Layers API follows the Keras layers API conventions. That is, aside from a different prefix, all functions in the Layers API have the same names and signatures as their counterparts in the Keras layers API.
一种 TensorFlow API,用于以层组合的方式构建深度神经网络。通过 Layers API,您可以构建不同类型的层,例如:
- 通过
tf.layers.Dense构建全连接层。 - 通过
tf.layers.Conv2D构建卷积层。
在编写自定义 Estimator 时,您可以编写“层”对象来定义所有隐藏层的特征。
Layers API 遵循 Keras layers API 规范。也就是说,除了前缀不同以外,Layers API 中的所有函数均与 Keras layers API 中的对应函数具有相同的名称和签名。
learning rate
A scalar used to train a model via gradient descent. During each iteration, the gradient descent algorithm multiplies the learning rate by the gradient. The resulting product is called the gradient step.
Learning rate is a key hyperparameter.
在训练模型时用于梯度下降的一个变量。在每次迭代期间,梯度下降法都会将学习速率与梯度相乘。得出的乘积称为梯度步长。
学习速率是一个重要的超参数。
least squares regression
A linear regression model trained by minimizing L2 Loss.
一种通过最小化 L2 损失训练出的线性回归模型。
linear regression
A type of regression model that outputs a continuous value from a linear combination of input features.
一种回归模型,通过将输入特征进行线性组合,以连续值作为输出。
logistic regression
A model that generates a probability for each possible discrete label value in classification problems by applying a sigmoid function to a linear prediction. Although logistic regression is often used in binary classification problems, it can also be used in multi-class classification problems (where it becomes called multi-class logistic regression or multinomial regression).
一种模型,通过将 S 型函数应用于线性预测,生成分类问题中每个可能的离散标签值的概率。虽然逻辑回归经常用于二元分类问题,但也可用于多类别分类问题(其叫法变为多类别逻辑回归或多项回归)。
Log Loss
The loss function used in binary logistic regression.
loss
A measure of how far a model’s predictions are from its label. Or, to phrase it more pessimistically, a measure of how bad the model is. To determine this value, a model must define a loss function. For example, linear regression models typically use mean squared error for a loss function, while logistic regression models use Log Loss.
一种衡量指标,用于衡量模型的预测偏离其标签的程度。或者更悲观地说是衡量模型有多差。要确定此值,模型必须定义损失函数。例如,线性回归模型通常将均方误差用于损失函数,而逻辑回归模型则使用对数损失函数。
M
machine learning
A program or system that builds (trains) a predictive model from input data. The system uses the learned model to make useful predictions from new (never-before-seen) data drawn from the same distribution as the one used to train the model. Machine learning also refers to the field of study concerned with these programs or systems.
一种程序或系统,用于根据输入数据构建(训练)预测模型。这种系统会利用学到的模型根据从分布(训练该模型时使用的同一分布)中提取的新数据(以前从未见过的数据)进行实用的预测。机器学习还指与这些程序或系统相关的研究领域。
mAP
平均精度均值,衡量学出的模型在所有类别上的好坏。
$$mAP = {\sum_{i=1}^{C}AP_i \over C} $$
其中,$C$ 表示类别的数量。
Mean Squared Error (MSE)
The average squared loss per example. MSE is calculated by dividing the squared loss by the number of examples. The values that TensorFlow Playground displays for “Training loss” and “Test loss” are MSE.
每个样本的平均平方损失。MSE 的计算方法是平方损失除以样本数。TensorFlow Playground 显示的“训练损失”值和“测试损失”值都是 MSE。
metric
A number that you care about. May or may not be directly optimized in a machine-learning system. A metric that your system tries to optimize is called an objective.
您关心的一个数值。可能可以也可能不可以直接在机器学习系统中得到优化。您的系统尝试优化的指标称为目标。
Metrics API (tf.metrics)
A TensorFlow API for evaluating models. For example, tf.metrics.accuracy determines how often a model’s predictions match labels. When writing a custom Estimator, you invoke Metrics API functions to specify how your model should be evaluated.
一种用于评估模型的 TensorFlow API。例如,tf.metrics.accuracy 用于确定模型的预测与标签匹配的频率。在编写自定义 Estimator 时,您可以调用 Metrics API 函数来指定应如何评估您的模型。
mini-batch
A small, randomly selected subset of the entire batch of examples run together in a single iteration of training or inference. The batch size of a mini-batch is usually between 10 and 1,000. It is much more efficient to calculate the loss on a mini-batch than on the full training data.
从训练或推断过程的一次迭代中一起运行的整批样本内随机选择的一小部分。小批次的规模通常介于 10 到 1000 之间。与基于完整的训练数据计算损失相比,基于小批次数据计算损失要高效得多。
mini-batch stochastic gradient descent (SGD)
A gradient descent algorithm that uses mini-batches. In other words, mini-batch SGD estimates the gradient based on a small subset of the training data. Vanilla SGD uses a mini-batch of size 1.
一种采用小批次样本的梯度下降法。也就是说,小批次 SGD 会根据一小部分训练数据来估算梯度。Vanilla SGD 使用的小批次的规模为 1。
ML
Abbreviation for machine learning.
机器学习的缩写。
model
The representation of what an ML system has learned from the training data. This is an overloaded term, which can have either of the following two related meanings:
- The TensorFlow graph that expresses the structure of how a prediction will be computed.
- The particular weights and biases of that TensorFlow graph, which are determined by training.
机器学习系统从训练数据学到的内容的表示形式。多含义术语,可以理解为下列两种相关含义之一:
- 一种 TensorFlow 图,用于表示预测计算结构。
- 该 TensorFlow 图的特定权重和偏差,通过训练决定。
model training
The process of determining the best model.
确定最佳模型的过程。
Momentum
A sophisticated gradient descent algorithm in which a learning step depends not only on the derivative in the current step, but also on the derivatives of the step(s) that immediately preceded it. Momentum involves computing an exponentially weighted moving average of the gradients over time, analogous to momentum in physics. Momentum sometimes prevents learning from getting stuck in local minima.
一种先进的梯度下降法,其中学习步长不仅取决于当前步长的导数,还取决于之前一步或多步的步长的导数。动量涉及计算梯度随时间而变化的指数级加权移动平均值,与物理学中的动量类似。动量有时可以防止学习过程被卡在局部最小的情况。
multi-class classification
Classification problems that distinguish among more than two classes. For example, there are approximately 128 species of maple trees, so a model that categorized maple tree species would be multi-class. Conversely, a model that divided emails into only two categories (spam and not spam) would be a binary classification model.
区分两种以上类别的分类问题。例如,枫树大约有 128 种,因此,确定枫树种类的模型就属于多类别模型。反之,仅将电子邮件分为两类(“垃圾邮件”和“非垃圾邮件”)的模型属于二元分类模型。
multinomial classification
Synonym for multi-class classification.
是多类别分类的同义词。
N
N-gram
N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念。 假设有一个字符串 s,那么该字符串的 N-Gram 就表示按长度 N 切分原词得到的词段, 也就是 s 中所有长度为 N 的子字符串序列。
设想如果有两个字符串,然后分别求它们的N-Gram, 那么就可以从它们的共有子串的数量这个角度去定义两个字符串间的 N-Gram 距离。 N-Gram 距离可以初步评价两个字符串的相似程度。
NaN trap
When one number in your model becomes a NaN during training, which causes many or all other numbers in your model to eventually become a NaN.
NaN is an abbreviation for “Not a Number.”
模型中的一个数字在训练期间变成 NaN,这会导致模型中的很多或所有其他数字最终也会变成 NaN。
NaN 是“非数字”的缩写。
negative class
In binary classification, one class is termed positive and the other is termed negative. The positive class is the thing we’re looking for and the negative class is the other possibility. For example, the negative class in a medical test might be “not tumor.” The negative class in an email classifier might be “not spam.” See also positive class.
在二元分类中,一种类别称为正类别,另一种类别称为负类别。正类别是我们要寻找的类别,负类别则是另一种可能性。例如,在医学检查中,负类别可以是“非肿瘤”。在电子邮件分类器中,负类别可以是“非垃圾邮件”。另请参阅正类别。
neural network
A model that, taking inspiration from the brain, is composed of layers (at least one of which is hidden) consisting of simple connected units or neurons followed by nonlinearities.
一种模型,灵感来源于脑部结构,由多个层构成(至少有一个是隐藏层),每个层都包含简单相连的单元或神经元(具有非线性关系)。
neuron
A node in a neural network, typically taking in multiple input values and generating one output value. The neuron calculates the output value by applying an activation function (nonlinear transformation) to a weighted sum of input values.
神经网络中的节点,通常是接收多个输入值并生成一个输出值。神经元通过将激活函数(非线性转换)应用于输入值的加权和来计算输出值。
node
An overloaded term that means either of the following:
- A neuron in a hidden layer.
- An operation in a TensorFlow graph.
多含义术语,可以理解为下列两种含义之一:
normalization
The process of converting an actual range of values into a standard range of values, typically -1 to +1 or 0 to 1. For example, suppose the natural range of a certain feature is 800 to 6,000. Through subtraction and division, you can normalize those values into the range -1 to +1.
See also scaling.
将实际的值区间转换为标准的值区间(通常为 -1 到 +1 或 0 到 1)的过程。例如,假设某个特征的自然区间是 800 到 6000。通过减法和除法运算,您可以将这些值标准化为位于 -1 到 +1 区间内。
另请参阅缩放。
numerical data
Features represented as integers or real-valued numbers. For example, in a real estate model, you would probably represent the size of a house (in square feet or square meters) as numerical data. Representing a feature as numerical data indicates that the feature’s values have a mathematical relationship to each other and possibly to the label. For example, representing the size of a house as numerical data indicates that a 200 square-meter house is twice as large as a 100 square-meter house. Furthermore, the number of square meters in a house probably has some mathematical relationship to the price of the house.
Not all integer data should be represented as numerical data. For example, postal codes in some parts of the world are integers; however, integer postal codes should not be represented as numerical data in models. That’s because a postal code of 20000 is not twice (or half) as potent as a postal code of 10000. Furthermore, although different postal codes do correlate to different real estate values, we can’t assume that real estate values at postal code 20000 are twice as valuable as real estate values at postal code 10000. Postal codes should be represented as categorical data instead.
Numerical features are sometimes called continuous features.
用整数或实数表示的特征。例如,在房地产模型中,您可能会用数值数据表示房子大小(以平方英尺或平方米为单位)。如果用数值数据表示特征,则可以表明特征的值相互之间具有数学关系,并且与标签可能也有数学关系。例如,如果用数值数据表示房子大小,则可以表明面积为 200 平方米的房子是面积为 100 平方米的房子的两倍。此外,房子面积的平方米数可能与房价存在一定的数学关系。
并非所有整数数据都应表示成数值数据。例如,世界上某些地区的邮政编码是整数,但在模型中,不应将整数邮政编码表示成数值数据。这是因为邮政编码 20000 在效力上并不是邮政编码 10000 的两倍(或一半)。此外,虽然不同的邮政编码确实与不同的房地产价值有关,但我们也不能假设邮政编码为 20000 的房地产在价值上是邮政编码为 10000 的房地产的两倍。邮政编码应表示成分类数据。
数值特征有时称为连续特征。
numpy
An open-source math library that provides efficient array operations in Python. pandas is built on numpy.
一个开放源代码数学库,在 Python 中提供高效的数组操作。Pandas 就建立在 Numpy 之上。
O
objective
A metric that your algorithm is trying to optimize.
算法尝试优化的指标。
offline inference
Generating a group of predictions, storing those predictions, and then retrieving those predictions on demand. Contrast with online inference.
生成一组预测,存储这些预测,然后根据需求检索这些预测。与在线推断相对。
one-hot encoding
A sparse vector in which:
- One element is set to 1.
- All other elements are set to 0.
One-hot encoding is commonly used to represent strings or identifiers that have a finite set of possible values. For example, suppose a given botany data set chronicles 15,000 different species, each denoted with a unique string identifier. As part of feature engineering, you’ll probably encode those string identifiers as one-hot vectors in which the vector has a size of 15,000.
一种稀疏向量,其中:
- 一个元素设为 1。
- 所有其他元素均设为 0。
one-hot 编码常用于表示拥有有限个可能值的字符串或标识符。例如,假设某个指定的植物学数据集记录了 15000 个不同的物种,其中每个物种都用独一无二的字符串标识符来表示。在特征工程过程中,您可能需要将这些字符串标识符编码为 one-hot 向量,向量的大小为 15000。
one-vs.-all
Given a classification problem with N possible solutions, a one-vs.-all solution consists of N separate binary classifiers—one binary classifier for each possible outcome. For example, given a model that classifies examples as animal, vegetable, or mineral, a one-vs.-all solution would provide the following three separate binary classifiers:
- animal vs. not animal
- vegetable vs. not vegetable
- mineral vs. not mineral
假设某个分类问题有 N 种可能的解决方案,一对多解决方案将包含 N 个单独的二元分类器 - 一个二元分类器对应一种可能的结果。例如,假设某个模型用于区分样本属于动物、蔬菜还是矿物,一对多解决方案将提供下列三个单独的二元分类器:
- 动物和非动物
- 蔬菜和非蔬菜
- 矿物和非矿物
online inference
Generating predictions on demand. Contrast with offline inference.
Operation (op)
A node in the TensorFlow graph. In TensorFlow, any procedure that creates, manipulates, or destroys a Tensor is an operation. For example, a matrix multiply is an operation that takes two Tensors as input and generates one Tensor as output.
TensorFlow 图中的节点。在 TensorFlow 中,任何创建、操纵或销毁张量的过程都属于操作。例如,矩阵相乘就是一种操作,该操作以两个张量作为输入,并生成一个张量作为输出。
optimizer
A specific implementation of the gradient descent algorithm. TensorFlow’s base class for optimizers is tf.train.Optimizer. Different optimizers may leverage one or more of the following concepts to enhance the effectiveness of gradient descent on a given training set:
- momentum (Momentum)
- update frequency (AdaGrad = ADAptive GRADient descent; Adam = ADAptive with Momentum; RMSProp)
- sparsity/regularization (Ftrl)
- more complex math (Proximal, and others)
You might even imagine an NN-driven optimizer.
梯度下降法的一种具体实现。TensorFlow 的优化器基类是 tf.train.Optimizer。不同的优化器(tf.train.Optimizer 的子类)会考虑如下概念:
- 动量 (Momentum)
- 更新频率 (AdaGrad = ADAptive GRADient descent; Adam = ADAptive with Momentum;RMSProp)
- 稀疏性/正则化 (Ftrl)
- 更复杂的计算方法 (Proximal, 等等)
甚至还包括 NN 驱动的优化器。
outliers
Values distant from most other values. In machine learning, any of the following are outliers:
- Weights with high absolute values.
- Predicted values relatively far away from the actual values.
- Input data whose values are more than roughly 3 standard deviations from the mean.
Outliers often cause problems in model training.
与大多数其他值差别很大的值。在机器学习中,下列所有值都是离群值。
- 绝对值很高的权重。
- 与实际值相差很大的预测值。
- 值比平均值高大约 3 个标准偏差的输入数据。
离群值常常会导致模型训练出现问题。
output layer
The “final” layer of a neural network. The layer containing the answer(s).
神经网络的“最后”一层,也是包含答案的层。
overfitting
Creating a model that matches the training data so closely that the model fails to make correct predictions on new data.
创建的模型与训练数据过于匹配,以致于模型无法根据新数据做出正确的预测。
P
pandas
A column-oriented data analysis API. Many ML frameworks, including TensorFlow, support pandas data structures as input. See pandas documentation.
面向列的数据分析 API。很多机器学习框架(包括 TensorFlow)都支持将 Pandas 数据结构作为输入。请参阅 Pandas 文档。
parameter
A variable of a model that the ML system trains on its own. For example, weights are parameters whose values the ML system gradually learns through successive training iterations. Contrast with hyperparameter.
机器学习系统自行训练的模型的变量。例如,权重就是一种参数,它们的值是机器学习系统通过连续的训练迭代逐渐学习到的。与超参数相对。
Parameter Server (PS)
A job that keeps track of a model’s parameters in a distributed setting.
一种作业,负责在分布式设置中跟踪模型参数。
parameter update
The operation of adjusting a model’s parameters during training, typically within a single iteration of gradient descent.
在训练期间(通常是在梯度下降法的单次迭代中)调整模型参数的操作。
partial derivative
A derivative in which all but one of the variables is considered a constant. For example, the partial derivative of f(x, y) with respect to x is the derivative of f considered as a function of x alone (that is, keeping y constant). The partial derivative of f with respect to x focuses only on how x is changing and ignores all other variables in the equation.
一种导数,除一个变量之外的所有变量都被视为常量。例如,f(x, y) 对 x 的偏导数就是 f(x) 的导数(即,使 y 保持恒定)。f 对 x 的偏导数仅关注 x 如何变化,而忽略公式中的所有其他变量。
partitioning strategy
The algorithm by which variables are divided across parameter servers.
参数服务器中分割变量的算法。
performance
Overloaded term with the following meanings:
- The traditional meaning within software engineering. Namely: How fast (or efficiently) does this piece of software run?
- The meaning within ML. Here, performance answers the following question: How correct is this model? That is, how good are the model’s predictions?
多含义术语,具有以下含义:
- 在软件工程中的传统含义。即:相应软件的运行速度有多快(或有多高效)?
- 在机器学习中的含义。在机器学习领域,性能旨在回答以下问题:相应模型的准确度有多高?即模型在预测方面的表现有多好?
perplexity
One measure of how well a model is accomplishing its task. For example, suppose your task is to read the first few letters of a word a user is typing on a smartphone keyboard, and to offer a list of possible completion words. Perplexity, P, for this task is approximately the number of guesses you need to offer in order for your list to contain the actual word the user is trying to type.
Perplexity is related to cross-entropy as follows:
一种衡量指标,用于衡量模型能够多好地完成任务。例如,假设任务是读取用户使用智能手机键盘输入字词时输入的前几个字母,然后列出一组可能的完整字词。此任务的困惑度 (P) 是:为了使列出的字词中包含用户尝试输入的实际字词,您需要提供的猜测项的个数。
困惑度与交叉熵的关系如下:
$$P= 2^{-\text{cross entropy}}$$
pipeline
The infrastructure surrounding a machine learning algorithm. A pipeline includes gathering the data, putting the data into training data files, training one or more models, and exporting the models to production.
机器学习算法的基础架构。流水线包括收集数据、将数据放入训练数据文件、训练一个或多个模型,以及将模型导出到生产环境。
positive class
In binary classification, the two possible classes are labeled as positive and negative. The positive outcome is the thing we’re testing for. (Admittedly, we’re simultaneously testing for both outcomes, but play along.) For example, the positive class in a medical test might be “tumor.” The positive class in an email classifier might be “spam.”
Contrast with negative class.
在二元分类中,两种可能的类别分别被标记为正类别和负类别。正类别结果是我们要测试的对象。(不可否认的是,我们会同时测试这两种结果,但只关注正类别结果。)例如,在医学检查中,正类别可以是“肿瘤”。在电子邮件分类器中,正类别可以是“垃圾邮件”。
与负类别相对。
precision
A metric for classification models. Precision identifies the frequency with which a model was correct when predicting the positive class. That is:
中文常称为:查准率、准确率。 对应的指标为:召回率recall
$$\text{Precision} = \frac{\text{True Positives}} {\text{True Positives} + \text{False Positives}}$$
prediction
A model’s output when provided with an input example.
模型在收到输入的样本后的输出。
prediction bias
A value indicating how far apart the average of predictions is from the average of labels in the data set.
一个值,用于表明预测平均值与数据集中标签的平均值相差有多大。
pre-made Estimator
An Estimator that someone has already built. TensorFlow provides several pre-made Estimators, including DNNClassifier, DNNRegressor, and LinearClassifier. You may build your own pre-made Estimators by following these instructions.
其他人已建好的 Estimator。TensorFlow 提供了一些预创建的 Estimator,包括 DNNClassifier、DNNRegressor 和 LinearClassifier。您可以按照这些说明构建自己预创建的 Estimator。
pre-trained model
Models or model components (such as embeddings) that have been already been trained. Sometimes, you’ll feed pre-trained embeddings into a neural network. Other times, your model will train the embeddings itself rather than rely on the pre-trained embeddings.
已经过训练的模型或模型组件(例如嵌套)。有时,您需要将预训练的嵌套馈送到神经网络。在其他时候,您的模型将自行训练嵌套,而不依赖于预训练的嵌套。
prior belief
What you believe about the data before you begin training on it. For example, L2 regularization relies on a prior belief that weights should be small and normally distributed around zero.
在开始采用相应数据进行训练之前,您对这些数据抱有的信念。例如,L2 正则化依赖的先验信念是权重应该很小且应以 0 为中心呈正态分布。
Q
queue
A TensorFlow Operation that implements a queue data structure. Typically used in I/O.
一种 TensorFlow 操作,用于实现队列数据结构。通常用于 I/O 中。
R
rank
Overloaded term in ML that can mean either of the following:
- The number of dimensions in a Tensor. For instance, a scalar has rank 0, a vector has rank 1, and a matrix has rank 2.
- The ordinal position of a class in an ML problem that categorizes classes from highest to lowest. For example, a behavior ranking system could rank a dog’s rewards from highest (a steak) to lowest (wilted kale).
机器学习中的一个多含义术语,可以理解为下列含义之一:
- 张量中的维度数量。例如,标量等级为 0,向量等级为 1,矩阵等级为 2。
- 在将类别从最高到最低进行排序的机器学习问题中,类别的顺序位置。例如,行为排序系统可以将狗狗的奖励从最高(牛排)到最低(枯萎的羽衣甘蓝)进行排序。
rater
A human who provides labels in examples. Sometimes called an “annotator.”
recall
A metric for classification models that answers the following question: Out of all the possible positive labels, how many did the model correctly identify? That is:
$$\text{Recall} = \frac{\text{True Positives}} {\text{True Positives} + \text{False Negatives}} $$
中文常称为:召回率、查全率。 相关指标为:查准率precision
一种分类模型指标,用于回答以下问题:在所有可能的正类别标签中,模型正确地识别出了多少个?即:
Rectified Linear Unit (ReLU)
An activation function with the following rules:
- If input is negative or zero, output is 0.
- If input is positive, output is equal to input.
一种激活函数,其规则如下:
- 如果输入为负数或 0,则输出 0。
- 如果输入为正数,则输出等于输入。
regression model
A type of model that outputs continuous (typically, floating-point) values. Compare with classification models, which output discrete values, such as “day lily” or “tiger lily.”
一种模型,能够输出连续的值(通常为浮点值)。请与分类模型进行比较,分类模型输出离散值,例如“黄花菜”或“虎皮百合”。
regularization
The penalty on a model’s complexity. Regularization helps prevent overfitting. Different kinds of regularization include:
- L1 regularization
- L2 regularization
- dropout regularization
- early stopping (this is not a formal regularization method, but can effectively limit overfitting)
对模型复杂度的惩罚。正则化有助于防止出现过拟合,包含以下类型:
regularization rate
A scalar value, represented as lambda, specifying the relative importance of the regularization function. The following simplified loss equation shows the regularization rate’s influence:
一种标量值,以 lambda 表示,用于指定正则化函数的相对重要性。从下面简化的损失公式中可以看出正则化率的影响:
$$\text{minimize(loss function + }\lambda\text{(regularization function))}$$
Raising the regularization rate reduces overfitting but may make the model less accurate.
representation
The process of mapping data to useful features.
将数据映射到实用特征的过程。
ROC (receiver operating characteristic) Curve
A curve of true positive rate vs. false positive rate at different classification thresholds. See also AUC.
不同分类阈值下的真正例率 或 真阳率和假正例率 或 假阳率构成的曲线。另请参阅曲线下面积。
ROC 翻成中文叫做受试者工作特征曲线,该术语由医疗领域引入。 它是把真正例率 或 真阳率 TP作为纵坐标,假正例率 或 假阳率 FP作为横坐标,对一个类别绘制的曲线。
曲线下的区域就是曲线下区域AUC(Area Under the Curve), 如果AUC的面积为1,表示在这个类别上你的准确率是最高的。AUC一般越大越好,说明某个类别的分类准确度越高。
ROI (region of interest)
目标检测领域术语,机器视觉、图像处理中,从被处理的图像以方框、圆、椭圆、不规则多边形等方式勾勒出需要处理的区域,称为感兴趣区域(ROI)。 这个区域是你的图像分析所关注的重点, 圈定该区域以便进行进一步处理。使用ROI圈定你想读的目标,可以减少处理时间,增加精度。
root directory
The directory you specify for hosting subdirectories of the TensorFlow checkpoint and events files of multiple models.
您指定的目录,用于托管多个模型的 TensorFlow 检查点和事件文件的子目录。
Root Mean Squared Error (RMSE)
The square root of the Mean Squared Error.
均方误差的平方根。
S
SavedModel
The recommended format for saving and recovering TensorFlow models. SavedModel is a language-neutral, recoverable serialization format, which enables higher-level systems and tools to produce, consume, and transform TensorFlow models.
See Saving and Restoring in the TensorFlow Programmer’s Guide for complete details.
保存和恢复 TensorFlow 模型时建议使用的格式。SavedModel 是一种独立于语言且可恢复的序列化格式,使较高级别的系统和工具可以创建、使用和转换 TensorFlow 模型。
如需完整的详细信息,请参阅《TensorFlow 编程人员指南》中的保存和恢复。
Saver
A TensorFlow object responsible for saving model checkpoints.
一种 TensorFlow 对象,负责保存模型检查点。
scaling
A commonly used practice in feature engineering to tame a feature’s range of values to match the range of other features in the data set. For example, suppose that you want all floating-point features in the data set to have a range of 0 to 1. Given a particular feature’s range of 0 to 500, you could scale that feature by dividing each value by 500.
See also normalization.
特征工程中的一种常用做法,是对某个特征的值区间进行调整,使之与数据集中其他特征的值区间一致。例如,假设您希望数据集中所有浮点特征的值都位于 0 到 1 区间内,如果某个特征的值位于 0 到 500 区间内,您就可以通过将每个值除以 500 来缩放该特征。
另请参阅标准化。
scikit-learn
A popular open-source ML platform. See www.scikit-learn.org.
一个热门的开放源代码机器学习平台。请访问 www.scikit-learn.org。
semi-supervised learning
Training a model on data where some of the training examples have labels but others don’t. One technique for semi-supervised learning is to infer labels for the unlabeled examples, and then to train on the inferred labels to create a new model. Semi-supervised learning can be useful if labels are expensive to obtain but unlabeled examples are plentiful.
训练模型时采用的数据中,某些训练样本有标签,而其他样本则没有标签。半监督式学习采用的一种技术是推断无标签样本的标签,然后使用推断出的标签进行训练,以创建新模型。如果获得有标签样本需要高昂的成本,而无标签样本则有很多,那么半监督式学习将非常有用。
sequence model
A model whose inputs have a sequential dependence. For example, predicting the next video watched from a sequence of previously watched videos.
一种模型,其输入具有序列依赖性。例如,根据之前观看过的一系列视频对观看的下一个视频进行预测。
session
Maintains state (for example, variables) within a TensorFlow program.
维持 TensorFlow 程序中的状态(例如变量)。
sigmoid function
A function that maps logistic or multinomial regression output (log odds) to probabilities, returning a value between 0 and 1. The sigmoid function has the following formula:
一种函数,可将逻辑回归输出或多项回归输出(对数几率)映射到概率,以返回介于 0 到 1 之间的值。S 型函数的公式如下:
$$y = \frac{1}{1 + e^{-\sigma}}$$
where $\sigma$ in logistic regression problems is simply:
在逻辑回归问题中,$\sigma$ 非常简单:
$$\sigma = b + w_1x_1 + w_2x_2 + … w_nx_n$$
In other words, the sigmoid function converts $\sigma$ into a probability between 0 and 1.
换句话说,S 型函数可将 $\sigma$ 转换为介于 0 到 1 之间的概率。
In some neural networks, the sigmoid function acts as the activation function.
softmax
A function that provides probabilities for each possible class in a multi-class classification model. The probabilities add up to exactly 1.0. For example, softmax might determine that the probability of a particular image being a dog at 0.9, a cat at 0.08, and a horse at 0.02. (Also called full softmax.)
Contrast with candidate sampling.
一种函数,可提供多类别分类模型中每个可能类别的概率。这些概率的总和正好为 1.0。例如,softmax 可能会得出某个图像是狗、猫和马的概率分别是 0.9、0.08 和 0.02。(也称为完整 softmax。)
与候选采样相对。
sparse feature
Feature vector whose values are predominately zero or empty. For example, a vector containing a single 1 value and a million 0 values is sparse. As another example, words in a search query could also be a sparse feature—there are many possible words in a given language, but only a few of them occur in a given query.
Contrast with dense feature.
一种特征向量,其中的大多数值都为 0 或为空。例如,某个向量包含一个为 1 的值和一百万个为 0 的值,则该向量就属于稀疏向量。再举一个例子,搜索查询中的单词也可能属于稀疏特征 - 在某种指定语言中有很多可能的单词,但在某个指定的查询中仅包含其中几个。
与密集特征相对。
squared hinge loss
The square of the hinge loss. Squared hinge loss penalizes outliers more harshly than regular hinge loss.
合页损失函数的平方。与常规合页损失函数相比,平方合页损失函数对离群值的惩罚更严厉。
squared loss
The loss function used in linear regression. (Also known as L2 Loss.) This function calculates the squares of the difference between a model’s predicted value for a labeled example and the actual value of the label. Due to squaring, this loss function amplifies the influence of bad predictions. That is, squared loss reacts more strongly to outliers than L1 loss.
在线性回归中使用的损失函数(也称为 L2 损失函数)。该函数可计算模型为有标签样本预测的值和标签的实际值之差的平方。由于取平方值,因此该损失函数会放大不佳预测的影响。也就是说,与 L1 损失函数相比,平方损失函数对离群值的反应更强烈。
static model
A model that is trained offline.
离线训练的一种模型。
stationarity
A property of data in a data set, in which the data distribution stays constant across one or more dimensions. Most commonly, that dimension is time, meaning that data exhibiting stationarity doesn’t change over time. For example, data that exhibits stationarity doesn’t change from September to December.
数据集中数据的一种属性,表示数据分布在一个或多个维度保持不变。这种维度最常见的是时间,即表明平稳性的数据不随时间而变化。例如,从 9 月到 12 月,表明平稳性的数据没有发生变化。
step
A forward and backward evaluation of one batch.
对一个批次的向前和向后评估。
step size
Synonym for learning rate.
是学习速率的同义词。
stochastic gradient descent (SGD)
A gradient descent algorithm in which the batch size is one. In other words, SGD relies on a single example chosen uniformly at random from a data set to calculate an estimate of the gradient at each step.
批次规模为 1 的一种梯度下降法。换句话说,SGD 依赖于从数据集中随机均匀选择的单个样本来计算每步的梯度估算值。
structural risk minimization (SRM)
An algorithm that balances two goals:
- The desire to build the most predictive model (for example, lowest loss).
- The desire to keep the model as simple as possible (for example, strong regularization).
For example, a model function that minimizes loss+regularization on the training set is a structural risk minimization algorithm.
For more information, see http://www.svms.org/srm/.
Contrast with empirical risk minimization.
一种算法,用于平衡以下两个目标:
- 期望构建最具预测性的模型(例如损失最低)。
- 期望使模型尽可能简单(例如强大的正则化)。
例如,旨在将基于训练集的损失和正则化降至最低的模型函数就是一种结构风险最小化算法。
如需更多信息,请参阅 http://www.svms.org/srm/。
与经验风险最小化相对。
summary
In TensorFlow, a value or set of values calculated at a particular step, usually used for tracking model metrics during training.
在 TensorFlow 中的某一步计算出的一个值或一组值,通常用于在训练期间跟踪模型指标。
supervised machine learning
Training a model from input data and its corresponding labels. Supervised machine learning is analogous to a student learning a subject by studying a set of questions and their corresponding answers. After mastering the mapping between questions and answers, the student can then provide answers to new (never-before-seen) questions on the same topic. Compare with unsupervised machine learning.
根据输入数据及其对应的标签来训练模型。监督式机器学习类似于学生通过研究一系列问题及其对应的答案来学习某个主题。在掌握了问题和答案之间的对应关系后,学生便可以回答关于同一主题的新问题(以前从未见过的问题)。请与非监督式机器学习进行比较。
synthetic feature
A feature that is not present among the input features, but is derived from one or more of them. Kinds of synthetic features include the following:
- Multiplying one feature by itself or by other feature(s). (These are termed feature crosses.)
- Dividing one feature by a second feature.
- Bucketing a continuous feature into range bins.
Features created by normalizing or scaling alone are not considered synthetic features.
一种特征,不在输入特征之列,而是从一个或多个输入特征衍生而来。合成特征包括以下类型:
T
target
Synonym for label.
是标签的同义词。
temporal data
Data recorded at different points in time. For example, winter coat sales recorded for each day of the year would be temporal data.
在不同时间点记录的数据。例如,记录的一年中每一天的冬外套销量就属于时态数据。
Tensor
The primary data structure in TensorFlow programs. Tensors are N-dimensional (where N could be very large) data structures, most commonly scalars, vectors, or matrices. The elements of a Tensor can hold integer, floating-point, or string values.
TensorFlow 程序中的主要数据结构。张量是 N 维(其中 N 可能非常大)数据结构,最常见的是标量、向量或矩阵。张量的元素可以包含整数值、浮点值或字符串值。
Tensor Processing Unit (TPU)
An ASIC (application-specific integrated circuit) that optimizes the performance of TensorFlow programs.
一种 ASIC(应用专用集成电路),用于优化 TensorFlow 程序的性能。
Tensor rank
See rank.
Tensor shape
The number of elements a Tensor contains in various dimensions. For example, a [5, 10] Tensor has a shape of 5 in one dimension and 10 in another.
张量在各种维度中包含的元素数。例如,张量 [5, 10] 在一个维度中的形状为 5,在另一个维度中的形状为 10。
Tensor size
The total number of scalars a Tensor contains. For example, a [5, 10] Tensor has a size of 50.
张量包含的标量总数。例如,张量 [5, 10] 的大小为 50。
TensorBoard
The dashboard that displays the summaries saved during the execution of one or more TensorFlow programs.
一个信息中心,用于显示在执行一个或多个 TensorFlow 程序期间保存的摘要信息。
TensorFlow
A large-scale, distributed, machine learning platform. The term also refers to the base API layer in the TensorFlow stack, which supports general computation on dataflow graphs.
Although TensorFlow is primarily used for machine learning, you may also use TensorFlow for non-ML tasks that require numerical computation using dataflow graphs.
一个大型的分布式机器学习平台。该术语还指 TensorFlow 堆栈中的基本 API 层,该层支持对数据流图进行一般计算。
虽然 TensorFlow 主要应用于机器学习领域,但也可用于需要使用数据流图进行数值计算的非机器学习任务。
TensorFlow Playground
A program that visualizes how different hyperparameters influence model (primarily neural network) training. Go to http://playground.tensorflow.org to experiment with TensorFlow Playground.
一款用于直观呈现不同的超参数对模型(主要是神经网络)训练的影响的程序。要试用 TensorFlow Playground,请前往 http://playground.tensorflow.org。
TensorFlow Serving
A platform to deploy trained models in production.
一个平台,用于将训练过的模型部署到生产环境。
test set
The subset of the data set that you use to test your model after the model has gone through initial vetting by the validation set.
Contrast with training set and validation set.
数据集的子集,用于在模型经由验证集的初步验证之后测试模型。
tf.Example
A standard protocol buffer for describing input data for machine learning model training or inference.
一种标准的 proto buffer,旨在描述用于机器学习模型训练或推断的输入数据。
time series analysis
A subfield of machine learning and statistics that analyzes temporal data. Many types of machine learning problems require time series analysis, including classification, clustering, forecasting, and anomaly detection. For example, you could use time series analysis to forecast the future sales of winter coats by month based on historical sales data.
机器学习和统计学的一个子领域,旨在分析时态数据。很多类型的机器学习问题都需要时间序列分析,其中包括分类、聚类、预测和异常检测。例如,您可以利用时间序列分析根据历史销量数据预测未来每月的冬外套销量。
training
The process of determining the ideal parameters comprising a model.
确定构成模型的理想参数的过程。
training set
The subset of the data set used to train a model.
Contrast with validation set and test set.
数据集的子集,用于训练模型。
transfer learning
Transferring information from one machine learning task to another. For example, in multi-task learning, a single model solves multiple tasks, such as a deep model that has different output nodes for different tasks. Transfer learning might involve transferring knowledge from the solution of a simpler task to a more complex one, or involve transferring knowledge from a task where there is more data to one where there is less data.
Most machine learning systems solve a single task. Transfer learning is a baby step towards artificial intelligence in which a single program can solve multiple tasks.
将信息从一个机器学习任务转移到另一个机器学习任务。例如,在多任务学习中,一个模型可以完成多项任务,例如针对不同任务具有不同输出节点的深度模型。转移学习可能涉及将知识从较简单任务的解决方案转移到较复杂的任务,或者将知识从数据较多的任务转移到数据较少的任务。
大多数机器学习系统都只能完成一项任务。转移学习是迈向人工智能的一小步;在人工智能中,单个程序可以完成多项任务。
true negative (TN)
An example in which the model correctly predicted the negative class. For example, the model inferred that a particular email message was not spam, and that email message really was not spam.
被模型正确地预测为负类别的样本。例如,模型推断出某封电子邮件不是垃圾邮件,而该电子邮件确实不是垃圾邮件。
true positive (TP)
An example in which the model correctly predicted the positive class. For example, the model inferred that a particular email message was spam, and that email message really was spam.
被模型正确地预测为正类别的样本。例如,模型推断出某封电子邮件是垃圾邮件,而该电子邮件确实是垃圾邮件。
true positive rate (TP rate)
Synonym for recall. That is:
是召回率的同义词,即:
$$\text{True Positive Rate} = \frac{\text{True Positives}} {\text{True Positives} + \text{False Negatives}}$$
True positive rate is the y-axis in an ROC curve.
真正例率是 ROC 曲线的 y 轴。
U
unlabeled example
An example that contains features but no label. Unlabeled examples are the input to inference. In semi-supervised and unsupervised learning, unlabeled examples are used during training.
包含特征但没有标签的样本。无标签样本是用于进行推断的输入内容。在半监督式和非监督式学习中,无标签样本在训练期间被使用。
unpooling
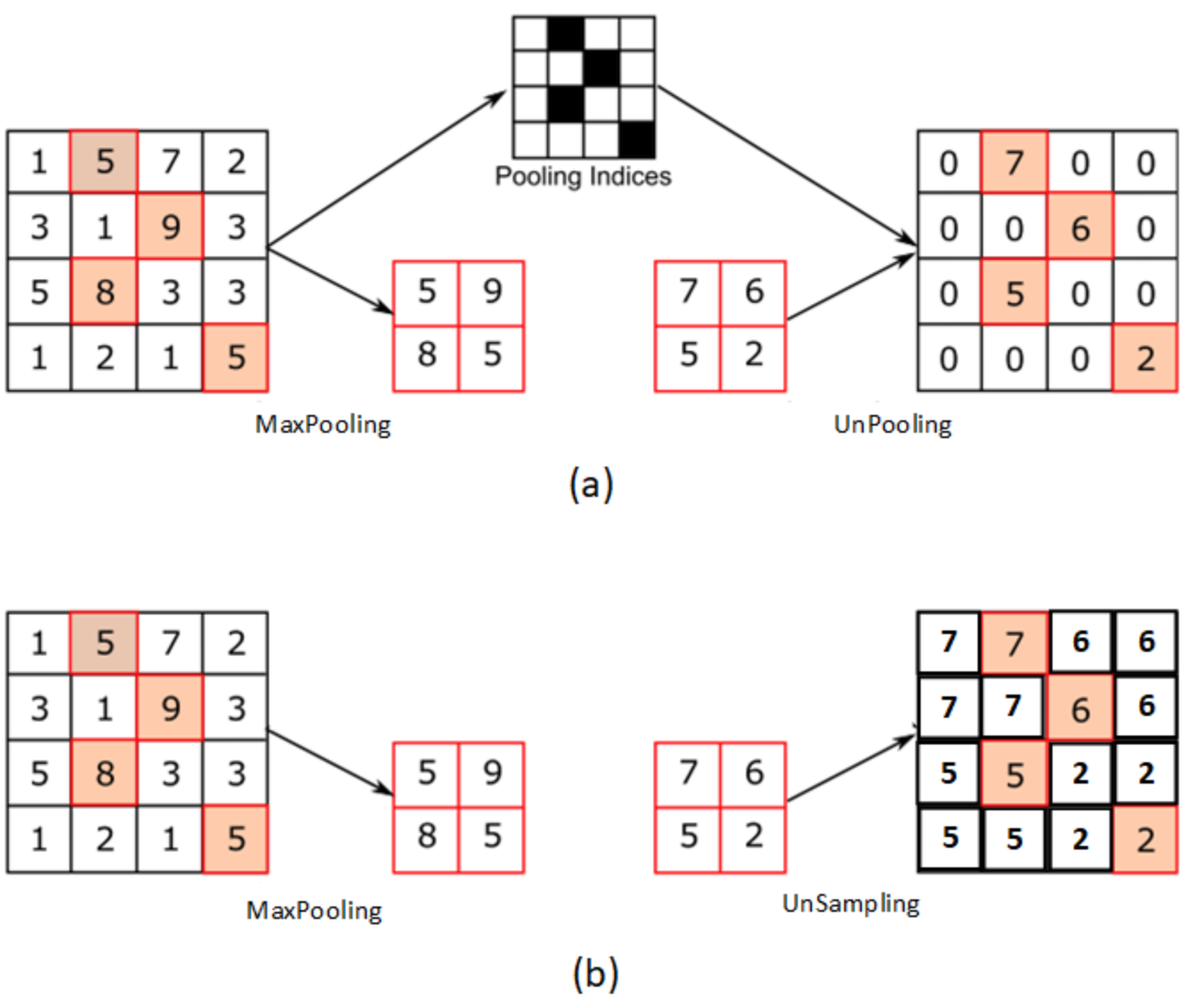
图(a)的特点是在最大池化(Maxpooling)的时候保留最大值的位置信息, 之后在反池化(unpooling)阶段使用该信息扩充 Feature Map,除最大值位置以外,其余补0。
图(b)的特点是反池化(unpooling)时没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充Feature Map。
unsupervised machine learning
Training a model to find patterns in a data set, typically an unlabeled data set.
The most common use of unsupervised machine learning is to cluster data into groups of similar examples. For example, an unsupervised machine learning algorithm can cluster songs together based on various properties of the music. The resulting clusters can become an input to other machine learning algorithms (for example, to a music recommendation service). Clustering can be helpful in domains where true labels are hard to obtain. For example, in domains such as anti-abuse and fraud, clusters can help humans better understand the data.
Another example of unsupervised machine learning is principal component analysis (PCA). For example, applying PCA on a data set containing the contents of millions of shopping carts might reveal that shopping carts containing lemons frequently also contain antacids.
Compare with supervised machine learning.
训练模型,以找出数据集(通常是无标签数据集)中的模式。
非监督式机器学习最常见的用途是将数据分为不同的聚类,使相似的样本位于同一组中。例如,非监督式机器学习算法可以根据音乐的各种属性将歌曲分为不同的聚类。所得聚类可以作为其他机器学习算法(例如音乐推荐服务)的输入。在很难获取真标签的领域,聚类可能会非常有用。例如,在反滥用和反欺诈等领域,聚类有助于人们更好地了解相关数据。
非监督式机器学习的另一个例子是主成分分析 (PCA)。例如,通过对包含数百万购物车中物品的数据集进行主成分分析,可能会发现有柠檬的购物车中往往也有抗酸药。
请与监督式机器学习进行比较。
V
validation set
A subset of the data set—disjunct from the training set—that you use to adjust hyperparameters.
Contrast with training set and test set.
数据集的一个子集,从训练集分离而来,用于调整超参数。
W
weight
A coefficient for a feature in a linear model, or an edge in a deep network. The goal of training a linear model is to determine the ideal weight for each feature. If a weight is 0, then its corresponding feature does not contribute to the model.
线性模型中特征的系数,或深度网络中的边。训练线性模型的目标是确定每个特征的理想权重。如果权重为 0,则相应的特征对模型来说没有任何贡献。
wide model
A linear model that typically has many sparse input features. We refer to it as “wide” since such a model is a special type of neural network with a large number of inputs that connect directly to the output node. Wide models are often easier to debug and inspect than deep models. Although wide models cannot express nonlinearities through hidden layers, they can use transformations such as feature crossing and bucketization to model nonlinearities in different ways.
Contrast with deep model.
一种线性模型,通常有很多稀疏输入特征。我们之所以称之为“宽度模型”,是因为这是一种特殊类型的神经网络,其大量输入均直接与输出节点相连。与深度模型相比,宽度模型通常更易于调试和检查。虽然宽度模型无法通过隐藏层来表示非线性关系,但可以利用特征组合、分桶等转换以不同的方式为非线性关系建模。
与深度模型相对。