TensorLayer 教程
Xiaoping Fan(译), freeopen(修订) 2017-09-09 [机器学习] #notesfreeopen: 为什么研究 TensorLayer ?
在TF的编码中,常看到model被封装成class,进一步研究,发现为了简化模型的创建,有各种封装库,包括Keras, Tflearn, TFSlim, tf.contrib.learn(或称skflow) 等。 其中TFSlim和skflow属TensorFlow自带,考虑到TFSlim中有现成的模型,就修改了一个试试,发现坑不小。我需要首先把数据源转成TFRecord格式,然后用模型训练后报错(out of range), 然后我就首先检查数据源的格式是否有问题,我采用TFSlim的Data provider来输出数据,可能我的数据维度太大,程序不报错,但一直死在那里不出结果,而同样我在使用numpy输出数据源数据时,没有任何问题,也没什么延时,瞬间我感觉到TFSlim的封装模式不仅把问题复杂化了,甚至还降低了程序的性能。Keras据说跑TF性能较慢,Tflearn感觉活跃度较低,考虑到TensorLayer是skflow上的再次封装,且不丧失灵活性,加上这篇最主要的教程写得真心不错,所以我发愿要好好研究一番。
为什么我总喜欢修订一些长文翻译?
技术翻译文章经常在阅读时有不知所云的现象,我总结的原因主要有三:一是译者没有理解作者意图,甚至连文章都没读懂,就开始直译,导致文理不通; 二是对技术术语不统一的称谓,本来英文是一个词,翻成中文后变成几个词,导致读者以为是不同的东西;三是过度翻译,把没必要或该省略的词也翻出来,反而影响理解。 比如vanilla RNN 中的vanilla, 并不代表“香草”,而是表示一个“普通的”或“原始的”意思,有时把这个词加进译文反而觉得多余,删掉最好。还有本文中“理解机器翻译-实现细节”部分的第6个段落,encoder_input_size 这个词,其实就是个代码变量,原译文居然也把它翻译出来,没有必要。我一般也是看到一点改一点,不保证能穷尽译文的所有地方,欢迎读者批评指正。
对于深度学习,该教程会引导您使用MNIST数据集构建不同的手写数字的分类器, 这可以说是神经网络的 “Hello World” 。 对于强化学习,我们将让计算机根据屏幕输入来学习打乒乓球。 对于自然语言处理。我们从词嵌套(word embedding)开始,然后再实现语言建模和机器翻译。 此外,TensorLayer的Tutorial包含了所有TensorFlow官方深度学习教程的模块化实现,因此你可以对照TensorFlow深度学习教程(英文|中文)来学习 。
若你已经对TensorFlow非常熟悉,阅读
InputLayer和DenseLayer的源代码可让您很好地理解 TensorLayer 是如何工作的。
在我们开始之前
本教程假定您在神经网络和 TensorFlow (TensorLayer在它的基础上构建的)方面具有一定的基础。 您可以尝试从Deeplearning Tutorial 同时进行学习。
对于人工神经网络更系统的介绍,我们推荐 Andrej Karpathy 等人所著的 Convolutional Neural Networks for Visual Recognition 和 Michael Nielsen 的 Neural Networks and Deep Learning。
要了解TensorFlow的更多内容,请阅读 TensorFlow tutorial 。 您不需要会它的全部,只要知道TensorFlow是如何工作的,就能够使用TensorLayer。 如果您是TensorFlow的新手,建议你阅读整个教程。
TensorLayer很简单
下面的代码是TensorLayer的一个简单例子,来自 tutorial_mnist_simple.py 。
我们提供了很多方便的函数(如: fit() ,test() ),但如果你想了解更多实现细节,或想成为机器学习领域的专家,我们鼓励
您尽可能地直接使用TensorFlow原本的方法如 sess.run() 来训练模型,请参考 tutorial_mnist.py 。
=
# 准备数据
, , , , , = \
# 定义 placeholder
=
=
# 定义模型
=
=
=
=
=
=
=
# 定义损失函数和衡量指标
# tl.cost.cross_entropy 在内部使用 tf.nn.sparse_softmax_cross_entropy_with_logits() 实现 softmax
=
=
=
=
=
# 定义 optimizer
=
=
# 初始化 session 中的所有参数
# 列出模型信息
# 训练模型
# 评估模型
# 把模型保存成 .npz 文件
运行MNIST例子

在本教程的第一部分,我们仅仅运行TensorLayer内置的MNIST例子。 MNIST数据集包含了60000个28x28像素的手写数字图片,它通常用于训练各种图片识别系统。
我们假设您已经按照 installation 安装好了TensorLayer。如果您还没有,请复制一个TensorLayer的source目录到终端中,并进入该文件夹,
然后运行 tutorial_mnist.py 这个例子脚本:
python tutorial_mnist.py
如果所有设置都正确,您将得到下面的结果:
: 0.300000
---
---
---
---
:
: : : 0.800000
: : 800,
: : : 0.500000
: : 800,
: : : 0.500000
: : 10,
0:
1:
2:
3:
4:
5:
: 1276810
0:
1:
2:
3:
4:
5:
: 0.000100
: 128
1 500 0.342539s
: 0.330111
: 0.298098
: 0.910700
10 500 0.356471s
: 0.085225
: 0.097082
: 0.971700
20 500 0.352137s
: 0.040741
: 0.070149
: 0.978600
30 500 0.350814s
: 0.022995
: 0.060471
: 0.982800
40 500 0.350996s
: 0.013713
: 0.055777
: 0.983700
...
这个例子脚本允许您从 if__name__=='__main__': 中选择不同的模型进行尝试,包括多层神经网络(Multi-Layer Perceptron),
退出(Dropout),退出连接(DropConnect),堆栈式降噪自编码器(Stacked Denoising Autoencoder)和卷积神经网络(CNN)。
main_test_layers(model='relu')
main_test_denoise_AE(model='relu')
main_test_stacked_denoise_AE(model='relu')
main_test_cnn_layer()
理解MNIST例子
现在就让我们看看它是如何做到的!跟着下面的步骤,打开源代码。
序言
您可能会首先注意到,除TensorLayer之外,我们还导入了Numpy和TensorFlow:
import tensorflow as tf
import tensorlayer as tl
from tensorlayer.layers import set_keep
import numpy as np
import time
这是因为TensorLayer是建立在TensorFlow上的,TensorLayer设计的初衷是为了简化工作并提供帮助而不是取代TensorFlow。 所以您会需要一起使用TensorLayer和一些常见的TensorFlow代码。
请注意,当使用降噪自编码器(Denoising Autoencoder)时,代码中的 set_keep 被当作用来访问保持概率(Keeping Probabilities)的占位符。
载入数据
下面第一部分的代码首先定义了 load_mnist_dataset() 函数。
其目的是为了下载MNIST数据集(如果还未下载),并且返回标准numpy数列通过numpy array的格式。
到这里还没有涉及TensorLayer,所以我们可以把它简单看作:
X_train, y_train, X_val, y_val, X_test, y_test = \
tl.files.load_mnist_dataset(shape=(-1,784))
X_train.shape 为 (50000,784),可以理解成共有50000张图片并且每张图片有784个像素点。
Y_train.shape 为 (50000,) ,它是一个和 X_train 长度相同的向量,用于给出每幅图的数字标签,即这些图片所包含的位于0-9之间的数字(如果画这些数字的人没有想乱画别的东西)。
另外对于卷积神经网络的例子,MNIST还可以按下面的4D版本来载入:
X_train, y_train, X_val, y_val, X_test, y_test = \
tl.files.load_mnist_dataset(shape=(-1, 28, 28, 1))
X_train.shape 为 (50000,28,28,1) ,这代表了50000张图片,每张图片使用一个通道(Channel),28行,28列。
通道为1是因为它是灰度图像,每个像素只能有一个值。
建立模型
来到这里,就轮到TensorLayer来一显身手了!TensorLayer允许您通过创建,堆叠或者合并图层(Layers)来定义任意结构的神经网络。 每一层都知道它在网络中的直接输入层, 而每层的输出同时作为该层和整个网络的一个句柄, 通常是我们要传递给其余代码的唯一东西。
freeopen: 上段的最后一句翻译,我认为原文中的output layer说法有问题,因为output layer通常指网络的最后一层, 或者表示当前层的下一层,这里应该表示为“每层的输出”才符合上下文,也符合代码逻辑。
正如上文提到的, tutorial_mnist.py 支持四类模型,我们通过同样的接口实现,只需简单的替换一下函数即可。
首先,我们将定义一个结构固定的多层次感知器(Multi-Layer Perceptron),所有的步骤都会详细的讲解。
然后,我们会实现一个去噪自编码器(Denosing Autoencoding)。
接着,我们要将所有去噪自编码器堆叠起来并对他们进行监督微调(Supervised Fine-tune)。
最后,我们将展示如何去创建一个卷积神经网络(Convolutional Neural Network)。
此外,如果您有兴趣,我们还提供了一个简化版的MNIST例子在 tutorial_mnist_simple.py 中,和一个
CIFAR-10数据集的卷积神经网络(CNN)的例子在 tutorial_cifar10_tfrecord.py 中, 供你参考。
多层神经网络
第一个脚本 main_test_layers() ,创建了一个具有两个隐藏层,每层800个单元的多层次感知器,并且具有10个单元的SOFTMAX输出层紧随其后。
它对输入数据采用20%的退出率(dropout)并且对隐藏层应用50%的退出率(dropout)。
为了提供数据给这个网络,TensorFlow占位符(placeholder)需要按如下定义。
在这里 None 是指在编译之后,网络将接受任意批规模(batchsize)的数据
x 是用来存放 X_train 数据的并且 y_ 是用来存放 y_train 数据的。
如果你已经知道批规模,那就不需要这种灵活性了。您可以在这里给出批规模,特别是对于卷积层,这样可以运用TensorFlow一些优化功能。
x = tf.placeholder(tf.float32, shape=[None, 784], name='x')
y_ = tf.placeholder(tf.int64, shape=[None, ], name='y_')
在TensorLayer中每个神经网络的基础是一个 InputLayer 实例。它代表了将要提供(feed)给网络的输入数据。
值得注意的是 InputLayer 并不依赖任何特定的数据。
network = tl.layers.InputLayer(x, name='input_layer')
在添加第一层隐藏层之前,我们要对输入数据应用20%的退出率(dropout)。
这里我们是通过一个 DropoutLayer 的实例来实现的。
network = tl.layers.DropoutLayer(network, keep=0.8, name='drop1')
请注意构造函数的第一个参数是输入层,第二个参数是激活值的保持概率(keeping probability for the activation value)
现在我们要继续构造第一个800个单位的全连接的隐藏层。
尤其是当要堆叠一个 DenseLayer 时,要特别注意。
network = tl.layers.DenseLayer(network, n_units=800, act = tf.nn.relu, name='relu1')
同样,构造函数的第一个参数意味着这我们正在 network 之上堆叠 network 。
n_units 简明得给出了全连接层的单位数。
act 指定了一个激活函数,这里的激活函数有一部分已经被定义在了tensorflow.nn 和 tensorlayer.activation 中。
我们在这里选择了整流器(rectifier),我们将得到ReLUs。
我们现在来添加50%的退出率,以及另外800个单位的稠密层(dense layer),和50%的退出率:
network = tl.layers.DropoutLayer(network, keep=0.5, name='drop2')
network = tl.layers.DenseLayer(network, n_units=800, act = tf.nn.relu, name='relu2')
network = tl.layers.DropoutLayer(network, keep=0.5, name='drop3')
最后,我们加入n_units等于分类个数的全连接的输出层。注意,cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(y, y_)) 在内部实现 Softmax,以提高计算效率,因此最后一层的输出为 identity ,更多细节请参考 tl.cost.cross_entropy() 。
network = tl.layers.DenseLayer(network,
n_units=10,
act = tl.activation.identity,
name='output_layer')
如上所述,因为每一层都被链接到了它的输入层,所以我们只需要在TensorLayer中将输出层接入一个网络:
y = network.outputs
y_op = tf.argmax(tf.nn.softmax(y), 1)
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(y, y_))
在这里,network.outputs 是网络的10个特征的输出(按照一个热门的格式)。
y_op 是代表类索引的整数输出, cost 是目标和预测标签的交叉熵。
降噪自编码器
自编码器是一种无监督学习(Unsupervisered Learning)模型,可从数据中学习出更好的表达, 目前已经用于逐层贪婪的预训练(Greedy layer-wise pre-train)。 有关自编码器内容,请参考教程 Deeplearning Tutorial。
脚本 main_test_denoise_AE() 实现了有50%的腐蚀率(corrosion rate)的降噪自编码器。
这个自编码器可以按如下方式定义,这里的 DenseLayer 代表了一个自编码器:
network = tl.layers.InputLayer(x, name='input_layer')
network = tl.layers.DropoutLayer(network, keep=0.5, name='denoising1')
network = tl.layers.DenseLayer(network, n_units=200, act=tf.nn.sigmoid, name='sigmoid1')
recon_layer1 = tl.layers.ReconLayer(network,
x_recon=x,
n_units=784,
act=tf.nn.sigmoid,
name='recon_layer1')
训练 DenseLayer ,只需要运行 ReconLayer.Pretrain() 即可。
如果要使用降噪自编码器,腐蚀层(corrosion layer)(DropoutLayer)的名字需要按后面说的指定。
如果要保存特征图像,设置 save 为 True 。
根据不同的架构和应用这里可以设置许多预训练的度量(metric)
对于 sigmoid型激活函数来说,自编码器可以用KL散度来实现。
而对于整流器(Rectifier)来说,对激活函数输出的L1正则化能使得输出变得稀疏。
所以 ReconLayer 默认只对整流激活函数(ReLU)提供KLD和交叉熵这两种损失度量,而对sigmoid型激活函数提供均方误差以及激活输出的L1范数这两种损失度量。
我们建议您修改 ReconLayer 来实现自己的预训练度量。
recon_layer1.pretrain(sess,
x=x,
X_train=X_train,
X_val=X_val,
denoise_name='denoising1',
n_epoch=200,
batch_size=128,
print_freq=10,
save=True,
save_name='w1pre_')
此外,脚本 main_test_stacked_denoise_AE() 展示了如何将多个自编码器堆叠到一个网络,然后进行微调。
卷积神经网络
最后,main_test_cnn_layer() 脚本创建了两个CNN层和最大汇流阶段(max pooling stages),一个全连接的隐藏层和一个全连接的输出层。
首先,我们用 Conv2dLayer添加一个卷积层,它带有32个5x5的过滤器,紧接是2x2维度的最大池化。接着是64个5x5的过滤器的卷积层和同样的最大池化。之后,用`FlattenLayer`把4维输出转为1维向量,和50%的dropout在最后的隐层中。这里的?表示每批数量(batch_size)。
注,tutorial_mnist.py 中介绍了针对初学者的简化版的 CNN API。
network = tl.layers.InputLayer(x, name='input_layer')
network = tl.layers.Conv2dLayer(network,
act = tf.nn.relu,
shape = [5, 5, 1, 32], # 32 features for each 5x5 patch
strides=[1, 1, 1, 1],
padding='SAME',
name ='cnn_layer1') # output: (?, 28, 28, 32)
network = tl.layers.PoolLayer(network,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
pool = tf.nn.max_pool,
name ='pool_layer1',) # output: (?, 14, 14, 32)
network = tl.layers.Conv2dLayer(network,
act = tf.nn.relu,
shape = [5, 5, 32, 64], # 64 features for each 5x5 patch
strides=[1, 1, 1, 1],
padding='SAME',
name ='cnn_layer2') # output: (?, 14, 14, 64)
network = tl.layers.PoolLayer(network,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
pool = tf.nn.max_pool,
name ='pool_layer2',) # output: (?, 7, 7, 64)
network = tl.layers.FlattenLayer(network, name='flatten_layer')
# output: (?, 3136)
network = tl.layers.DropoutLayer(network, keep=0.5, name='drop1')
# output: (?, 3136)
network = tl.layers.DenseLayer(network, n_units=256, act = tf.nn.relu, name='relu1')
# output: (?, 256)
network = tl.layers.DropoutLayer(network, keep=0.5, name='drop2')
# output: (?, 256)
network = tl.layers.DenseLayer(network, n_units=10, act = tl.identity, name='output_layer')
# output: (?, 10)
对于专家们来说,
Conv2dLayer将使用tensorflow.nn.conv2d,TensorFlow默认的卷积方式来创建一个卷积层。
训练模型
在 tutorial_mnist.py 脚本的其余部分,仅使用交叉熵代价函数来对MNIST数据集进行训练循环。
数据集迭代
迭代函数分别对inputs 和 targets 两个numpy数组,按照小批量的数量尺度进行迭代。
更多有关迭代函数的说明,可以在 tensorlayer.iterate 中找到。
tl.iterate.minibatches(inputs, targets, batchsize, shuffle=False)
损失和更新公式
我们继续创建一个在训练中被最小化的损失表达式:
y = network.outputs
y_op = tf.argmax(tf.nn.softmax(y), 1)
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(y, y_))
举 main_test_layers() 这个例子来说,更多的成本或者正则化方法可以被应用在这里。
如果要在权重矩阵中应用最大模(max-norm)方法,你可以添加下列代码:
cost = cost + tl.cost.maxnorm_regularizer(1.0)(network.all_params[0]) +
tl.cost.maxnorm_regularizer(1.0)(network.all_params[2])
根据要解决的问题,您会需要使用不同的损失函数,更多有关损失函数的说明请见: tensorlayer.cost
有了模型和定义的损失函数之后,我们就可以创建用于训练网络的更新公式。 接下去,我们将使用TensorFlow的优化器如下:
train_params = network.all_params
train_op = tf.train.AdamOptimizer(learning_rate, beta1=0.9, beta2=0.999,
epsilon=1e-08, use_locking=False).minimize(cost, var_list=train_params)
为了训练网络,我们需要提供数据和保持概率给 feed_dict。
feed_dict = {x: X_train_a, y_: y_train_a}
feed_dict.update( network.all_drop )
sess.run(train_op, feed_dict=feed_dict)
同时为了进行验证和测试,我们这里用了略有不同的方法。
所有的Dropout,退连(DropConnect),腐蚀层(Corrosion Layers)都将被禁用。
tl.utils.dict_to_one 将会设置所有 network.all_drop 值为1。
dp_dict = tl.utils.dict_to_one( network.all_drop )
feed_dict = {x: X_test_a, y_: y_test_a}
feed_dict.update(dp_dict)
err, ac = sess.run([cost, acc], feed_dict=feed_dict)
最后,作为一个额外的监测量,我们需要创建一个分类准确度的公式:
correct_prediction = tf.equal(tf.argmax(y, 1), y_)
acc = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
下一步?
在 tutorial_cifar10_tfrecord.py 中我们还有更高级的图像分类的例子。
请阅读代码及注释,用以明白如何来生成更多的训练数据以及什么是局部响应正则化。
在这之后,您可以尝试着去实现 残差网络(Residual Network)。
小提示:您可能会用到Layer.outputs。
运行乒乓球例子
在本教程的第二部分,我们将运行一个深度强化学习的例子,它在Karpathy的两篇博客 Deep Reinforcement Learning:Pong from Pixels 有介绍。
python tutorial_atari_pong.py
在运行教程代码之前 你需要安装 OpenAI gym environment ,它是强化学习的一个标杆。 如果一切设置正确,您将得到一个类似以下的输出:
[2016-07-12 09:31:59,760] Making new env: Pong-v0
tensorlayer:Instantiate InputLayer input_layer (?, 6400)
tensorlayer:Instantiate DenseLayer relu1: 200, relu
tensorlayer:Instantiate DenseLayer output_layer: 3, identity
param 0: (6400, 200) (mean: -0.000009, median: -0.000018 std: 0.017393)
param 1: (200,) (mean: 0.000000, median: 0.000000 std: 0.000000)
param 2: (200, 3) (mean: 0.002239, median: 0.003122 std: 0.096611)
param 3: (3,) (mean: 0.000000, median: 0.000000 std: 0.000000)
num of params: 1280803
layer 0: Tensor("Relu:0", shape=(?, 200), dtype=float32)
layer 1: Tensor("add_1:0", shape=(?, 3), dtype=float32)
episode 0: game 0 took 0.17381s, reward: -1.000000
episode 0: game 1 took 0.12629s, reward: 1.000000 !!!!!!!!
episode 0: game 2 took 0.17082s, reward: -1.000000
episode 0: game 3 took 0.08944s, reward: -1.000000
episode 0: game 4 took 0.09446s, reward: -1.000000
episode 0: game 5 took 0.09440s, reward: -1.000000
episode 0: game 6 took 0.32798s, reward: -1.000000
episode 0: game 7 took 0.74437s, reward: -1.000000
episode 0: game 8 took 0.43013s, reward: -1.000000
episode 0: game 9 took 0.42496s, reward: -1.000000
episode 0: game 10 took 0.37128s, reward: -1.000000
episode 0: game 11 took 0.08979s, reward: -1.000000
episode 0: game 12 took 0.09138s, reward: -1.000000
episode 0: game 13 took 0.09142s, reward: -1.000000
episode 0: game 14 took 0.09639s, reward: -1.000000
episode 0: game 15 took 0.09852s, reward: -1.000000
episode 0: game 16 took 0.09984s, reward: -1.000000
episode 0: game 17 took 0.09575s, reward: -1.000000
episode 0: game 18 took 0.09416s, reward: -1.000000
episode 0: game 19 took 0.08674s, reward: -1.000000
episode 0: game 20 took 0.09628s, reward: -1.000000
resetting env. episode reward total was -20.000000. running mean: -20.000000
episode 1: game 0 took 0.09910s, reward: -1.000000
episode 1: game 1 took 0.17056s, reward: -1.000000
episode 1: game 2 took 0.09306s, reward: -1.000000
episode 1: game 3 took 0.09556s, reward: -1.000000
episode 1: game 4 took 0.12520s, reward: 1.000000 !!!!!!!!
episode 1: game 5 took 0.17348s, reward: -1.000000
episode 1: game 6 took 0.09415s, reward: -1.000000
这个例子让电脑从屏幕输入来学习如何像人类一样打乒乓球。 在经过15000个序列的训练之后,计算机就可以赢得20%的比赛。 在20000个序列的训练之后,计算机可以赢得35%的比赛, 我们可以看到计算机学的越来越快,这是因为它有更多的胜利的数据来进行训练。 如果您用30000个序列来训练它,那么它会一直赢。
render = False
resume = False
如果您想显示游戏过程,那就设置 render 为 True 。
当您再次运行该代码,您可以设置 resume 为 True,那么代码将加载现有的模型并且会基于它进行训练。

理解强化学习
乒乓球
要理解强化学习,我们要让电脑学习如何从原始的屏幕输入(像素输入)打乒乓球。 在我们开始之前,我们强烈建议您去浏览一个著名的博客叫做 Deep Reinforcement Learning:pong from Pixels , 这是使用python numpy库和OpenAI gym environment=来实现的一个深度强化学习的最简实现。
python tutorial_atari_pong.py
策略网络(Policy Network)
在深度强化学习中,Policy Network 等同于 深度神经网络。 它是我们的选手(或者说“代理人(agent)”),它的输出告诉我们应该做什么(向上移动或向下移动): 在Karpathy的代码中,他只定义了2个动作,向上移动和向下移动,并且仅使用单个simgoid输出: 为了使我们的教程更具有普遍性,我们使用3个 softmax 输出来定义向上移动,向下移动和停止(什么都不做)3个动作。
# observation for training
states_batch_pl = tf.placeholder(tf.float32, shape=[None, D])
network = tl.layers.InputLayer(states_batch_pl, name='input_layer')
network = tl.layers.DenseLayer(network, n_units=H,
act = tf.nn.relu, name='relu1')
network = tl.layers.DenseLayer(network, n_units=3,
act = tl.activation.identity, name='output_layer')
probs = network.outputs
sampling_prob = tf.nn.softmax(probs)
然后我们的代理人就一直打乒乓球。它计算不同动作的概率, 并且之后会从这个均匀的分布中选取样本(动作)。 因为动作被1,2和3代表,但是softmax输出应该从0开始,所以我们从-1计算这个标签的价值。
prob = sess.run(
sampling_prob,
feed_dict={states_batch_pl: x}
)
# action. 1: STOP 2: UP 3: DOWN
action = np.random.choice([1,2,3], p=prob.flatten())
...
ys.append(action - 1)
策略逼近(Policy Gradient)
策略梯度下降法是一个end-to-end的算法,它直接学习从状态映射到动作的策略函数。 一个近似最优的策略可以通过最大化预期的奖励来直接学习。 策略函数的参数(例如,在乒乓球例子终使用的策略网络的参数)在预期奖励的近似值的引导下能够被训练和学习。 换句话说,我们可以通过更新它的参数来逐步调整策略函数,这样它能从给定的状态做出一系列行为来获得更高的奖励。
策略迭代的一个替代算法就是深度Q-learning(DQN)。 他是基于Q-learning,学习一个映射状态和动作到一些值的价值函数的算法(叫Q函数)。 DQN采用了一个深度神经网络来作为Q函数的逼近来代表Q函数。 训练是通过最小化时序差分(temporal-difference)误差来实现。 一个名为“再体验(experience replay)”的神经生物学的启发式机制通常和DQN一起被使用来帮助提高非线性函数的逼近的稳定性
您可以阅读以下文档,来得到对强化学习更好的理解:
- Reinforcement Learning: An Introduction. Richard S. Sutton and Andrew G. Barto
- Deep Reinforcement Learning. David Silver, Google DeepMind
- UCL Course on RL
强化深度学习近些年来最成功的应用就是让模型去学习玩Atari的游戏。 AlphaGO同时也是使用类似的策略逼近方法来训练他们的策略网络而战胜了世界级的专业围棋选手。
- Atari - Playing Atari with Deep Reinforcement Learning
- Atari - Human-level control through deep reinforcement learning
- AlphaGO - Mastering the game of Go with deep neural networks and tree search
数据集迭代
在强化学习中,我们把每场比赛所产生的所有决策来作为一个序列 (up,up,stop,…,down)。在乒乓球游戏中,比赛是在某一方达到21分后结束的,所以一个序列可能包含几十个决策。 然后我们可以设置一个批规模的大小,每一批包含一定数量的序列,基于这个批规模来更新我们的模型。 在本教程中,我们把每批规模设置成10个序列。使用RMSProp训练一个具有200个单元的隐藏层的2层策略网络
损失和更新公式
接着我们创建一个在训练中被最小化的损失公式:
actions_batch_pl = tf.placeholder(tf.int32, shape=[None])
discount_rewards_batch_pl = tf.placeholder(tf.float32, shape=[None])
loss = tl.rein.cross_entropy_reward_loss(probs, actions_batch_pl,
discount_rewards_batch_pl)
...
...
sess.run(
train_op,
feed_dict={
states_batch_pl: epx,
actions_batch_pl: epy,
discount_rewards_batch_pl: disR
}
)
一batch的损失和一个batch内的策略网络的所有输出,所有的我们做出的动作和相应的被打折的奖励有关 我们首先通过累加被打折的奖励和实际输出和真实动作的交叉熵计算每一个动作的损失。 最后的损失是所有动作的损失的和。
下一步?
上述教程展示了您如何去建立自己的代理人,end-to-end。 虽然它有很合理的品质,但它的默认参数不会给你最好的代理人模型。 这有一些您可以优化的内容。
首先,与传统的MLP模型不同,比起 Playing Atari with Deep Reinforcement Learning 更好的是我们可以使用CNNs来采集屏幕信息
另外这个模型默认参数没有调整,您可以更改学习率,衰退率,或者用不同的方式来初始化您的模型的权重。
最后,您可以尝试不同任务(游戏)的模型。
运行Word2Vec例子
在教程的这一部分,我们训练一个词嵌套矩阵,每个词可以通过矩阵中唯一的行向量来表示。 在训练结束时,意思类似的单词会有相识的词向量。 在代码的最后,我们通过把单词放到一个平面上来可视化,我们可以看到相似的单词会被聚集在一起。
python tutorial_word2vec_basic.py
如果一切设置正确,您最后会得到如下的可视化图。
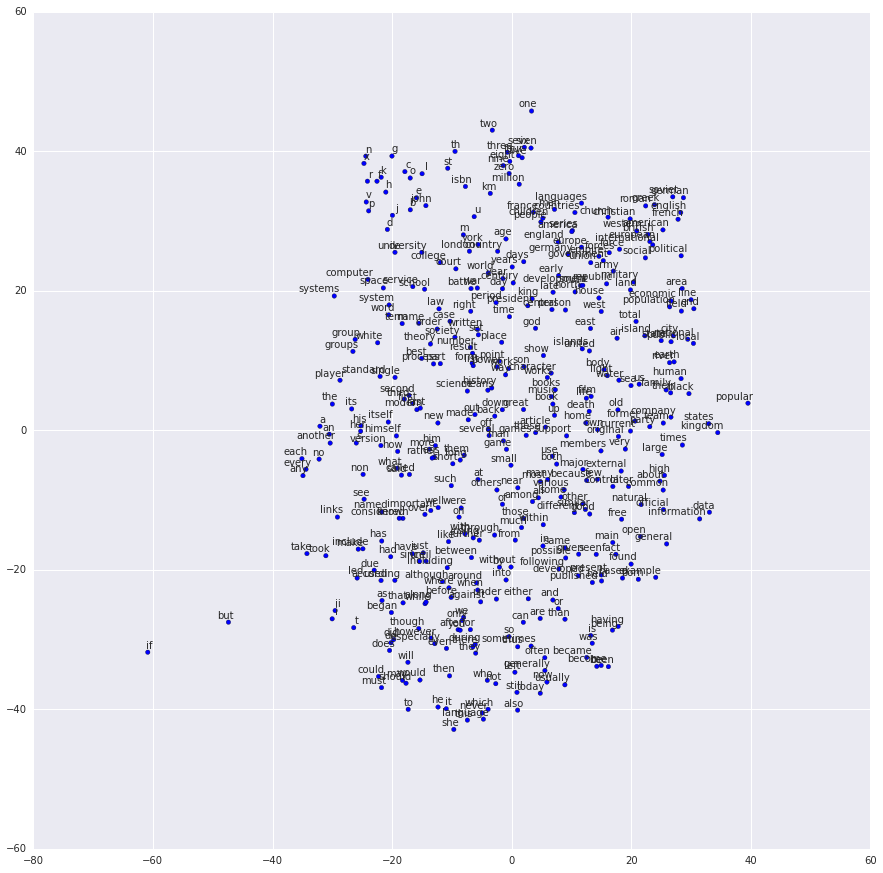
理解词嵌套
词嵌套(嵌入)
我们强烈建议您先阅读Colah的博客 Word Representations (中文翻译) , 以理解为什么我们要使用一个向量来表示一个单词。更多Word2vec的细节可以在 Word2vec Parameter Learning Explained 中找到。
基本来说,训练一个嵌套矩阵是一个非监督学习的过程。一个单词使用唯一的ID来表示,而这个ID号就是嵌套矩阵的行号(row index),对应的行向量就是用来表示该单词的,使用向量来表示单词可以更好地表达单词的意思。比如,有4个单词的向量, woman − man = queen - king ,这个例子中可以看到,嵌套矩阵中有一个纬度是用来表示性别的。
定义一个Word2vec词嵌套矩阵如下。
# train_inputs is a row vector, a input is an integer id of single word.
# train_labels is a column vector, a label is an integer id of single word.
# valid_dataset is a column vector, a valid set is an integer id of single word.
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# Look up embeddings for inputs.
emb_net = tl.layers.Word2vecEmbeddingInputlayer(
inputs = train_inputs,
train_labels = train_labels,
vocabulary_size = vocabulary_size,
embedding_size = embedding_size,
num_sampled = num_sampled,
nce_loss_args = {},
E_init = tf.random_uniform_initializer(minval=-1.0, maxval=1.0),
E_init_args = {},
nce_W_init = tf.truncated_normal_initializer(
stddev=float(1.0/np.sqrt(embedding_size))),
nce_W_init_args = {},
nce_b_init = tf.constant_initializer(value=0.0),
nce_b_init_args = {},
name ='word2vec_layer',
)
数据迭代和损失函数
Word2vec使用负采样(Negative sampling)和Skip-gram模型进行训练。
噪音对比估计损失(NCE)会帮助减少损失函数的计算量,加快训练速度。
Skip-Gram 将文本(context)和目标(target)反转,尝试从目标单词预测目标文本单词。
我们使用 tl.nlp.generate_skip_gram_batch 函数来生成训练数据,如下:
# NCE损失函数由 Word2vecEmbeddingInputlayer 提供
cost = emb_net.nce_cost
train_params = emb_net.all_params
train_op = tf.train.AdagradOptimizer(learning_rate, initial_accumulator_value=0.1,
use_locking=False).minimize(cost, var_list=train_params)
data_index = 0
while (step < num_steps):
batch_inputs, batch_labels, data_index = tl.nlp.generate_skip_gram_batch(
data=data, batch_size=batch_size, num_skips=num_skips,
skip_window=skip_window, data_index=data_index)
feed_dict = {train_inputs : batch_inputs, train_labels : batch_labels}
_, loss_val = sess.run([train_op, cost], feed_dict=feed_dict)
加载已训练好的的词嵌套矩阵
在训练嵌套矩阵的最后,我们保存矩阵及其词汇表、单词转ID字典、ID转单词字典。
然后,当下次做实际应用时,可以想下面的代码中那样加载这个已经训练好的矩阵和字典,
参考 tutorial_generate_text.py 。
vocabulary_size = 50000
embedding_size = 128
model_file_name = "model_word2vec_50k_128"
batch_size = None
print("Load existing embedding matrix and dictionaries")
all_var = tl.files.load_npy_to_any(name=model_file_name+'.npy')
data = all_var['data']; count = all_var['count']
dictionary = all_var['dictionary']
reverse_dictionary = all_var['reverse_dictionary']
tl.nlp.save_vocab(count, name='vocab_'+model_file_name+'.txt')
del all_var, data, count
load_params = tl.files.load_npz(name=model_file_name+'.npz')
x = tf.placeholder(tf.int32, shape=[batch_size])
y_ = tf.placeholder(tf.int32, shape=[batch_size, 1])
emb_net = tl.layers.EmbeddingInputlayer(
inputs = x,
vocabulary_size = vocabulary_size,
embedding_size = embedding_size,
name ='embedding_layer')
tl.layers.initialize_global_variables(sess)
tl.files.assign_params(sess, [load_params[0]], emb_net)
运行PTB例子
Penn TreeBank(PTB)数据集被用在很多语言建模(Language Modeling)的论文中,包括“Empirical Evaluation and Combination of Advanced Language Modeling Techniques“和 “Recurrent Neural Network Regularization”。该数据集的训练集有929k个单词,验证集有73K个单词,测试集有82k个单词。 在它的词汇表刚好有10k个单词。
PTB例子是为了展示如何用递归神经网络(Recurrent Neural Network)来进行语言建模的。
给一句话 “I am from Imperial College London”, 这个模型可以从中学习出如何从“from Imperial College”来预测出“Imperial College London”。也就是说,它根据之前输入的单词序列来预测出下一步输出的单词序列,在刚才的例子中 num_steps (序列长度,sequence length) 为 3。
python tutorial_ptb_lstm.py
该脚本提供三种设置(小,中,大),越大的模型有越好的建模性能,您可以修改下面的代码片段来选择不同的模型设置。
flags.DEFINE_string(
"model", "small",
"A type of model. Possible options are: small, medium, large.")
如果您选择小设置,您将会看到:
Epoch: 1 Learning rate: 1.000
0.004 perplexity: 5220.213 speed: 7635 wps
0.104 perplexity: 828.871 speed: 8469 wps
0.204 perplexity: 614.071 speed: 8839 wps
0.304 perplexity: 495.485 speed: 8889 wps
0.404 perplexity: 427.381 speed: 8940 wps
0.504 perplexity: 383.063 speed: 8920 wps
0.604 perplexity: 345.135 speed: 8920 wps
0.703 perplexity: 319.263 speed: 8949 wps
0.803 perplexity: 298.774 speed: 8975 wps
0.903 perplexity: 279.817 speed: 8986 wps
Epoch: 1 Train Perplexity: 265.558
Epoch: 1 Valid Perplexity: 178.436
...
Epoch: 13 Learning rate: 0.004
0.004 perplexity: 56.122 speed: 8594 wps
0.104 perplexity: 40.793 speed: 9186 wps
0.204 perplexity: 44.527 speed: 9117 wps
0.304 perplexity: 42.668 speed: 9214 wps
0.404 perplexity: 41.943 speed: 9269 wps
0.504 perplexity: 41.286 speed: 9271 wps
0.604 perplexity: 39.989 speed: 9244 wps
0.703 perplexity: 39.403 speed: 9236 wps
0.803 perplexity: 38.742 speed: 9229 wps
0.903 perplexity: 37.430 speed: 9240 wps
Epoch: 13 Train Perplexity: 36.643
Epoch: 13 Valid Perplexity: 121.475
Test Perplexity: 116.716
PTB例子证明了递归神经网络能够实现语言建模,但是这个例子并没有做什么实际的事情。 在做具体应用之前,您应该浏览这个例子的代码和下一章 “理解 LSTM” 来学好递归神经网络的基础。 之后,您将学习如何用递归神经网络来生成文本,如何实现语言翻译和问题应答系统。
理解LSTM
递归神经网络 (Recurrent Neural Network)
我们认为Andrey Karpathy的博客 Understand Recurrent Neural Network 是了解递归神经网络最好的材料。 读完这个博客后,Colah的博客 Understand LSTM Network 能帮助你了解LSTM。 我们在这里不介绍更多关于递归神经网络的内容,所以在你继续下面的内容之前,请先阅读我们建议阅读的博客。
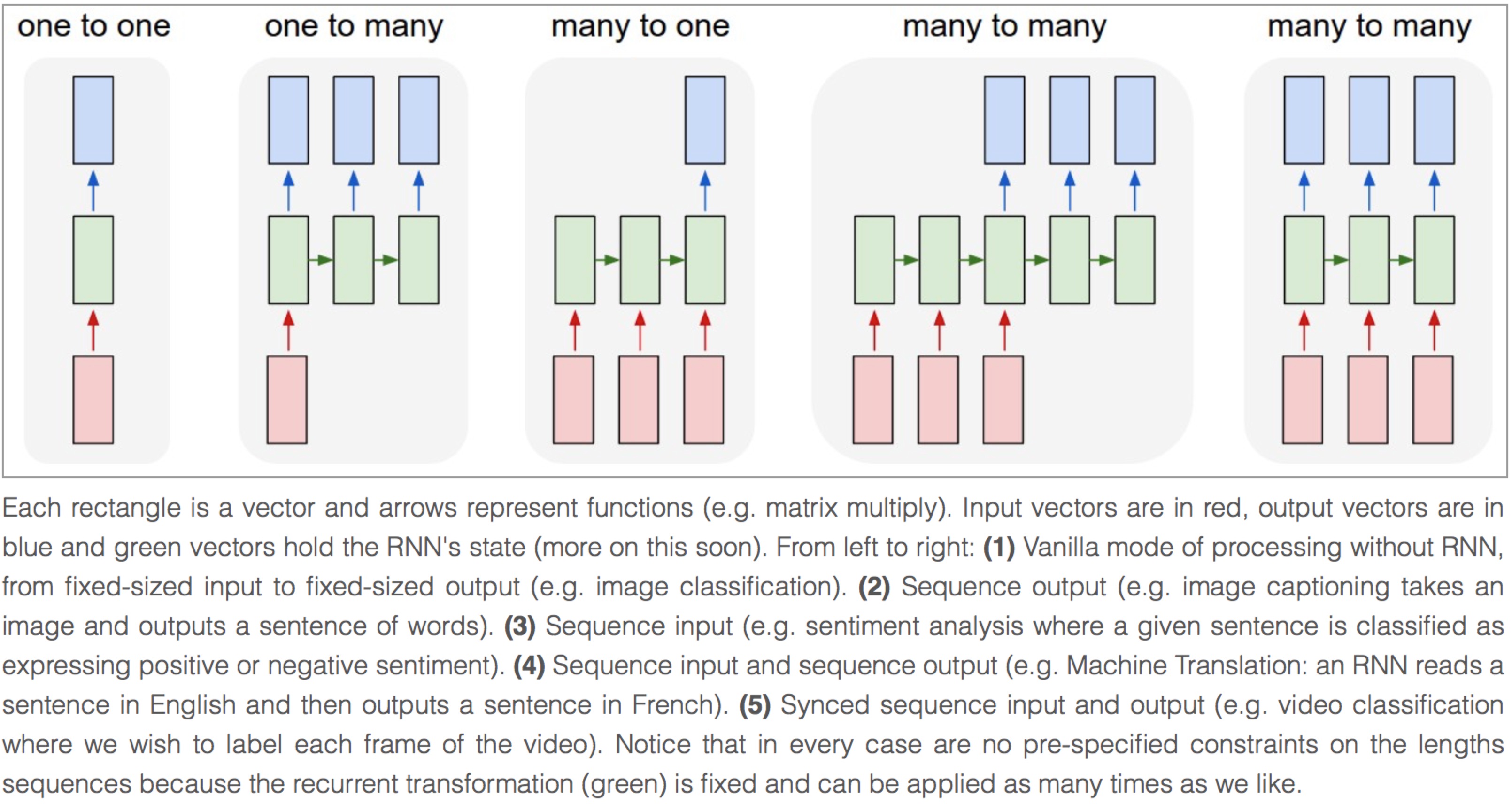
图片由Andrey Karpathy提供
同步输入与输出序列 (Synced sequence input and output)
PTB例子中的模型是一个典型的同步输入与输出,Karpathy 把它描述为 “(5) 同步序列输入与输出(例如视频分类中我们希望对每一帧进行标记)。“
模型的构建如下,第一层是词嵌套层(嵌入),把每一个单词转换成对应的词向量,在该例子中没有使用预先训练好的 嵌套矩阵。第二,堆叠两层LSTM,使用Dropout来实现规则化,防止overfitting。 最后,使用全连接层输出一序列的softmax输出。
第一层LSTM的输出形状是 [batch_size, num_steps, hidden_size],这是为了让下一层LSTM可以堆叠在其上面。 第二层LSTM的输出形状是 [batch_sizenum_steps, hidden_size],这是为了让输出层(全连接层 Dense)可以堆叠在其上面。 然后计算每个样本的softmax输出,样本总数为 n_examples = batch_sizenum_steps。
若想要更进一步理解该PTB教程,您也可以阅读 TensorFlow 官方的PTB教程 ,中文翻译请见极客学院。
network = tl.layers.EmbeddingInputlayer(
inputs = x,
vocabulary_size = vocab_size,
embedding_size = hidden_size,
E_init = tf.random_uniform_initializer(-init_scale, init_scale),
name ='embedding_layer')
if is_training:
network = tl.layers.DropoutLayer(network, keep=keep_prob, name='drop1')
network = tl.layers.RNNLayer(network,
cell_fn=tf.nn.rnn_cell.BasicLSTMCell,
cell_init_args={'forget_bias': 0.0},
n_hidden=hidden_size,
initializer=tf.random_uniform_initializer(-init_scale, init_scale),
n_steps=num_steps,
return_last=False,
name='basic_lstm_layer1')
lstm1 = network
if is_training:
network = tl.layers.DropoutLayer(network, keep=keep_prob, name='drop2')
network = tl.layers.RNNLayer(network,
cell_fn=tf.nn.rnn_cell.BasicLSTMCell,
cell_init_args={'forget_bias': 0.0},
n_hidden=hidden_size,
initializer=tf.random_uniform_initializer(-init_scale, init_scale),
n_steps=num_steps,
return_last=False,
return_seq_2d=True,
name='basic_lstm_layer2')
lstm2 = network
if is_training:
network = tl.layers.DropoutLayer(network, keep=keep_prob, name='drop3')
network = tl.layers.DenseLayer(network,
n_units=vocab_size,
W_init=tf.random_uniform_initializer(-init_scale, init_scale),
b_init=tf.random_uniform_initializer(-init_scale, init_scale),
act = tl.activation.identity, name='output_layer')
数据迭代
batch_size 数值可以被视为并行计算的数量。 如下面的例子所示,第一个 batch 使用 0 到 9 来学习序列信息。 第二个 batch 使用 10 到 19 来学习序列。 所以它忽略了 9 到 10 之间的信息。 只当我们 bath_size 设为 1,它才使用 0 到 20 之间所有的序列信息来学习。
这里的 batch_size 的意思与 MNIST 例子略有不同。 在 MNIST 例子,batch_size 是每次迭代中我们使用的样本数量, 而在 PTB 的例子中,batch_size 是为加快训练速度的并行进程数。
虽然当 batch_size > 1 时有些信息将会被忽略, 但是如果你的数据是足够长的(一个语料库通常有几十亿个字),被忽略的信息不会影响最终的结果。
在PTB教程中,我们设置了 batch_size = 20,所以,我们将整个数据集拆分成 20 段(segment)。 在每一轮(epoch)的开始时,我们有 20 个初始化的 LSTM 状态(State),然后分别对 20 段数据进行迭代学习。
训练数据迭代的例子如下:
train_data = [i for i in range(20)]
for batch in tl.iterate.ptb_iterator(train_data, batch_size=2, num_steps=3):
x, y = batch
print(x, '\n',y)
... [[ 0 1 2] <---x 1st subset/ iteration
... [10 11 12]]
... [[ 1 2 3] <---y
... [11 12 13]]
...
... [[ 3 4 5] <--- 1st batch input 2nd subset/ iteration
... [13 14 15]] <--- 2nd batch input
... [[ 4 5 6] <--- 1st batch target
... [14 15 16]] <--- 2nd batch target
...
... [[ 6 7 8] 3rd subset/ iteration
... [16 17 18]]
... [[ 7 8 9]
... [17 18 19]]
> 这个例子可以当作词嵌套矩阵的预训练。
损失和更新公式
损失函数是一系列输出cross entropy的均值。
# 更多细节请见 tensorlayer.cost.cross_entropy_seq()
def loss_fn(outputs, targets, batch_size, num_steps):
# Returns the cost function of Cross-entropy of two sequences, implement
# softmax internally.
# outputs : 2D tensor [batch_size*num_steps, n_units of output layer]
# targets : 2D tensor [batch_size, num_steps], need to be reshaped.
# n_examples = batch_size * num_steps
# so
# cost is the averaged cost of each mini-batch (concurrent process).
loss = tf.nn.seq2seq.sequence_loss_by_example(
[outputs],
[tf.reshape(targets, [-1])],
[tf.ones([batch_size * num_steps])])
cost = tf.reduce_sum(loss) / batch_size
return cost
# Cost for Training
cost = loss_fn(network.outputs, targets, batch_size, num_steps)
在训练时,该例子在若干个epoch之后(由 max_epoch 定义),才开始按比例下降学习率(learning rate),新学习率是前一个epoch的学习率乘以一个下降率(由 lr_decay 定义)。
此外,截断反向传播(truncated backpropagation)截断了
为使学习过程易于处理,通常的做法是将反向传播的梯度在(按时间)展开的步骤上照一个固定长度( num_steps )截断。 通过在一次迭代中的每个时刻上提供长度为 num_steps 的输入和每次迭代完成之后反向传导,这会很容易实现。
# 截断反响传播 Truncated Backpropagation for training
with tf.variable_scope('learning_rate'):
lr = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars),
max_grad_norm)
optimizer = tf.train.GradientDescentOptimizer(lr)
train_op = optimizer.apply_gradients(zip(grads, tvars))
如果当前epoch值大于 max_epoch ,则把当前学习率乘以 lr_decay 来降低学习率。
new_lr_decay = lr_decay ** max(i - max_epoch, 0.0)
sess.run(tf.assign(lr, learning_rate * new_lr_decay))
在每一个epoch的开始之前,LSTM的状态要被重置为零状态;在每一个迭代之后,LSTM状态都会被改变,所以要把最新的LSTM状态 作为下一个迭代的初始化状态。
# 在每一个epoch之前,把所有LSTM状态设为零状态
state1 = tl.layers.initialize_rnn_state(lstm1.initial_state)
state2 = tl.layers.initialize_rnn_state(lstm2.initial_state)
for step, (x, y) in enumerate(tl.iterate.ptb_iterator(train_data,
batch_size, num_steps)):
feed_dict = {input_data: x, targets: y,
lstm1.initial_state: state1,
lstm2.initial_state: state2,
}
# 启用dropout
feed_dict.update( network.all_drop )
# 把新的状态作为下一个迭代的初始状态
_cost, state1, state2, _ = sess.run([cost,
lstm1.final_state,
lstm2.final_state,
train_op],
feed_dict=feed_dict
)
costs += _cost; iters += num_steps
预测
在训练完模型之后,当我们预测下一个输出时,我们不需要考虑序列长度了,因此 batch_size 和 num_steps 都设为 1 。
然后,我们可以一步一步地输出下一个单词,而不是通过一序列的单词来输出一序列的单词。
input_data_test = tf.placeholder(tf.int32, [1, 1])
targets_test = tf.placeholder(tf.int32, [1, 1])
...
network_test, lstm1_test, lstm2_test = inference(input_data_test,
is_training=False, num_steps=1, reuse=True)
...
cost_test = loss_fn(network_test.outputs, targets_test, 1, 1)
...
print("Evaluation")
# 测试
# go through the test set step by step, it will take a while.
start_time = time.time()
costs = 0.0; iters = 0
# 与训练时一样,设置所有LSTM状态为零状态
state1 = tl.layers.initialize_rnn_state(lstm1_test.initial_state)
state2 = tl.layers.initialize_rnn_state(lstm2_test.initial_state)
for step, (x, y) in enumerate(tl.iterate.ptb_iterator(test_data,
batch_size=1, num_steps=1)):
feed_dict = {input_data_test: x, targets_test: y,
lstm1_test.initial_state: state1,
lstm2_test.initial_state: state2,
}
_cost, state1, state2 = sess.run([cost_test,
lstm1_test.final_state,
lstm2_test.final_state],
feed_dict=feed_dict
)
costs += _cost; iters += 1
test_perplexity = np.exp(costs / iters)
print("Test Perplexity: %.3f took %.2fs" % (test_perplexity, time.time() - start_time))
下一步?
您已经明白了同步序列输入和序列输出(Synced sequence input and output)。 现在让我们思考下序列输入单一输出的情况(Sequence input and one output), LSTM 也可以学会通过给定一序列输入如 “我来自北京,我会说..“ 来输出 一个单词 “中文”。
请仔细阅读并理解 tutorial_generate_text.py 的代码,它讲了如何加载一个已经训练好的词嵌套矩阵,
以及如何给定机器一个文档,让它来学习文字自动生成。
Karpathy的博客: “(3) Sequence input (e.g. sentiment analysis where a given sentence is classified as expressing positive or negative sentiment). “
运行机器翻译例子
python tutorial_translate.py
该脚本将训练一个神经网络来把英文翻译成法文。 如果一切正常,您将看到:
- 下载WMT英文-法文翻译数据库,包括训练集和测试集。
- 通过训练集创建英文和法文的词汇表。
- 把训练集和测试集的单词转换成数字ID表示。
Prepare raw data
Load or Download WMT English-to-French translation > wmt
Training data : wmt/giga-fren.release2
Testing data : wmt/newstest2013
Create vocabularies
Vocabulary of French : wmt/vocab40000.fr
Vocabulary of English : wmt/vocab40000.en
Creating vocabulary wmt/vocab40000.fr from data wmt/giga-fren.release2.fr
processing line 100000
processing line 200000
processing line 300000
processing line 400000
processing line 500000
processing line 600000
processing line 700000
processing line 800000
processing line 900000
processing line 1000000
processing line 1100000
processing line 1200000
...
processing line 22500000
Creating vocabulary wmt/vocab40000.en from data wmt/giga-fren.release2.en
processing line 100000
...
processing line 22500000
...
首先,我们从WMT’15网站上下载英语-法语翻译数据。训练数据和测试数据如下。 训练数据用于训练模型,测试数据用于评估该模型。
wmt/training-giga-fren.tar <-- 英文-法文训练集 (2.6GB)
giga-fren.release2.* 从该文件解压出来
wmt/dev-v2.tgz <-- 多种语言的测试集 (21.4MB)
newstest2013.* 从该文件解压出来
wmt/giga-fren.release2.fr <-- 法文训练集 (4.57GB)
wmt/giga-fren.release2.en <-- 英文训练集 (3.79GB)
wmt/newstest2013.fr <-- 法文测试集 (393KB)
wmt/newstest2013.en <-- 英文测试集 (333KB)
所有 giga-fren.release2.* 是训练数据, giga-fren.release2.fr 内容如下:
Il a transformé notre vie | Il a transformé la société | Son fonctionnement | La technologie, moteur du changement Accueil | Concepts | Enseignants | Recherche | Aperçu | Collaborateurs | Web HHCC | Ressources | Commentaires Musée virtuel du Canada
Plan du site
Rétroaction
Crédits
English
Qu’est-ce que la lumière?
La découverte du spectre de la lumière blanche Des codes dans la lumière Le spectre électromagnétique Les spectres d’émission Les spectres d’absorption Les années-lumière La pollution lumineuse
Le ciel des premiers habitants La vision contemporaine de l'Univers L’astronomie pour tous
Bande dessinée
Liens
Glossaire
Observatoires
...
giga-fren.release2.en 内容如下,我们可以看到单词或者句子用 | 或 \n 来分隔。
Changing Lives | Changing Society | How It Works | Technology Drives Change Home | Concepts | Teachers | Search | Overview | Credits | HHCC Web | Reference | Feedback Virtual Museum of Canada Home Page
Site map
Feedback
Credits
Français
What is light ?
The white light spectrum Codes in the light The electromagnetic spectrum Emission spectra Absorption spectra Light-years Light pollution
The sky of the first inhabitants A contemporary vison of the Universe Astronomy for everyone
Cartoon
Links
Glossary
Observatories
测试数据 newstest2013.en 和 newstest2013.fr 如下所示:
newstest2013.en :
A Republican strategy to counter the re-election of Obama
Republican leaders justified their policy by the need to combat electoral fraud.
However, the Brennan Centre considers this a myth, stating that electoral fraud is rarer in the United States than the number of people killed by lightning.
newstest2013.fr :
Une stratégie républicaine pour contrer la réélection d'Obama
Les dirigeants républicains justifièrent leur politique par la nécessité de lutter contre la fraude électorale.
Or, le Centre Brennan considère cette dernière comme un mythe, affirmant que la fraude électorale est plus rare aux États-Unis que le nombre de personnes tuées par la foudre.
下载完数据之后,开始创建词汇表文件。
从训练数据 giga-fren.release2.fr 和 giga-fren.release2.en创建 vocab40000.fr 和 vocab40000.en 这个过程需要较长一段时间,数字 40000 代表了词汇库的大小。
vocab40000.fr (381KB) 按下列所示地按每行一个单词的方式存储(one-item-per-line)。
_PAD
_GO
_EOS
_UNK
de
,
.
'
la
et
des
les
à
le
du
l
en
)
d
0
(
00
pour
dans
un
que
une
sur
au
0000
a
par
vocab40000.en (344KB) 也是如此。
_PAD
_GO
_EOS
_UNK
the
.
,
of
and
to
in
a
)
(
0
for
00
that
is
on
The
0000
be
by
with
or
:
as
"
000
are
;
接着我们开始创建英文和法文的数字化(ID)训练集和测试集。这也要较长一段时间。
Tokenize data
Tokenizing data in wmt/giga-fren.release2.fr <-- Training data of French
tokenizing line 100000
tokenizing line 200000
tokenizing line 300000
tokenizing line 400000
...
tokenizing line 22500000
Tokenizing data in wmt/giga-fren.release2.en <-- Training data of English
tokenizing line 100000
tokenizing line 200000
tokenizing line 300000
tokenizing line 400000
...
tokenizing line 22500000
Tokenizing data in wmt/newstest2013.fr <-- Testing data of French
Tokenizing data in wmt/newstest2013.en <-- Testing data of English
最后,我们所有的文件如下所示:
wmt/training-giga-fren.tar <-- 英文-法文训练集 (2.6GB)
giga-fren.release2.* 从该文件解压出来
wmt/dev-v2.tgz <-- 多种语言的测试集 (21.4MB)
newstest2013.* 从该文件解压出来
wmt/giga-fren.release2.fr <-- 法文训练集 (4.57GB)
wmt/giga-fren.release2.en <-- 英文训练集 (3.79GB)
wmt/newstest2013.fr <-- 法文测试集 (393KB)
wmt/newstest2013.en <-- 英文测试集 (333KB)
wmt/vocab40000.fr <-- 法文词汇表 (381KB)
wmt/vocab40000.en <-- 英文词汇表 (344KB)
wmt/giga-fren.release2.ids40000.fr <-- 数字化法文训练集 (2.81GB)
wmt/giga-fren.release2.ids40000.en <-- 数字化英文训练集 (2.38GB)
wmt/newstest2013.ids40000.fr <-- 数字化法文训练集 (268KB)
wmt/newstest2013.ids40000.en <-- 数字化英文测试集 (232KB)
现在,把数字化的数据读入buckets中,并计算不同buckets中数据样本的个数。
Read development (test) data into buckets
dev data: (5, 10) [[13388, 4, 949], [23113, 8, 910, 2]]
en word_ids: [13388, 4, 949]
en context: [b'Preventing', b'the', b'disease']
fr word_ids: [23113, 8, 910, 2]
fr context: [b'Pr\xc3\xa9venir', b'la', b'maladie', b'_EOS']
Read training data into buckets (limit: 0)
reading data line 100000
reading data line 200000
reading data line 300000
reading data line 400000
reading data line 500000
reading data line 600000
reading data line 700000
reading data line 800000
...
reading data line 22400000
reading data line 22500000
train_bucket_sizes: [239121, 1344322, 5239557, 10445326]
train_total_size: 17268326.0
train_buckets_scale: [0.013847375825543252, 0.09169638099257565, 0.3951164693091849, 1.0]
train data: (5, 10) [[1368, 3344], [1089, 14, 261, 2]]
en word_ids: [1368, 3344]
en context: [b'Site', b'map']
fr word_ids: [1089, 14, 261, 2]
fr context: [b'Plan', b'du', b'site', b'_EOS']
the num of training data in each buckets: [239121, 1344322, 5239557, 10445326]
the num of training data: 17268326
train_buckets_scale: [0.013847375825543252, 0.09169638099257565, 0.3951164693091849, 1.0]
最后开始训练模型,当 steps_per_checkpoint = 10 时,您将看到:
steps_per_checkpoint = 10
Create Embedding Attention Seq2seq Model
global step 10 learning rate 0.5000 step-time 22.26 perplexity 12761.50
eval: bucket 0 perplexity 5887.75
eval: bucket 1 perplexity 3891.96
eval: bucket 2 perplexity 3748.77
eval: bucket 3 perplexity 4940.10
global step 20 learning rate 0.5000 step-time 20.38 perplexity 28761.36
eval: bucket 0 perplexity 10137.01
eval: bucket 1 perplexity 12809.90
eval: bucket 2 perplexity 15758.65
eval: bucket 3 perplexity 26760.93
global step 30 learning rate 0.5000 step-time 20.64 perplexity 6372.95
eval: bucket 0 perplexity 1789.80
eval: bucket 1 perplexity 1690.00
eval: bucket 2 perplexity 2190.18
eval: bucket 3 perplexity 3808.12
global step 40 learning rate 0.5000 step-time 16.10 perplexity 3418.93
eval: bucket 0 perplexity 4778.76
eval: bucket 1 perplexity 3698.90
eval: bucket 2 perplexity 3902.37
eval: bucket 3 perplexity 22612.44
global step 50 learning rate 0.5000 step-time 14.84 perplexity 1811.02
eval: bucket 0 perplexity 644.72
eval: bucket 1 perplexity 759.16
eval: bucket 2 perplexity 984.18
eval: bucket 3 perplexity 1585.68
global step 60 learning rate 0.5000 step-time 19.76 perplexity 1580.55
eval: bucket 0 perplexity 1724.84
eval: bucket 1 perplexity 2292.24
eval: bucket 2 perplexity 2698.52
eval: bucket 3 perplexity 3189.30
global step 70 learning rate 0.5000 step-time 17.16 perplexity 1250.57
eval: bucket 0 perplexity 298.55
eval: bucket 1 perplexity 502.04
eval: bucket 2 perplexity 645.44
eval: bucket 3 perplexity 604.29
global step 80 learning rate 0.5000 step-time 18.50 perplexity 793.90
eval: bucket 0 perplexity 2056.23
eval: bucket 1 perplexity 1344.26
eval: bucket 2 perplexity 767.82
eval: bucket 3 perplexity 649.38
global step 90 learning rate 0.5000 step-time 12.61 perplexity 541.57
eval: bucket 0 perplexity 180.86
eval: bucket 1 perplexity 350.99
eval: bucket 2 perplexity 326.85
eval: bucket 3 perplexity 383.22
global step 100 learning rate 0.5000 step-time 18.42 perplexity 471.12
eval: bucket 0 perplexity 216.63
eval: bucket 1 perplexity 348.96
eval: bucket 2 perplexity 318.20
eval: bucket 3 perplexity 389.92
global step 110 learning rate 0.5000 step-time 18.39 perplexity 474.89
eval: bucket 0 perplexity 8049.85
eval: bucket 1 perplexity 1677.24
eval: bucket 2 perplexity 936.98
eval: bucket 3 perplexity 657.46
global step 120 learning rate 0.5000 step-time 18.81 perplexity 832.11
eval: bucket 0 perplexity 189.22
eval: bucket 1 perplexity 360.69
eval: bucket 2 perplexity 410.57
eval: bucket 3 perplexity 456.40
global step 130 learning rate 0.5000 step-time 20.34 perplexity 452.27
eval: bucket 0 perplexity 196.93
eval: bucket 1 perplexity 655.18
eval: bucket 2 perplexity 860.44
eval: bucket 3 perplexity 1062.36
global step 140 learning rate 0.5000 step-time 21.05 perplexity 847.11
eval: bucket 0 perplexity 391.88
eval: bucket 1 perplexity 339.09
eval: bucket 2 perplexity 320.08
eval: bucket 3 perplexity 376.44
global step 150 learning rate 0.4950 step-time 15.53 perplexity 590.03
eval: bucket 0 perplexity 269.16
eval: bucket 1 perplexity 286.51
eval: bucket 2 perplexity 391.78
eval: bucket 3 perplexity 485.23
global step 160 learning rate 0.4950 step-time 19.36 perplexity 400.80
eval: bucket 0 perplexity 137.00
eval: bucket 1 perplexity 198.85
eval: bucket 2 perplexity 276.58
eval: bucket 3 perplexity 357.78
global step 170 learning rate 0.4950 step-time 17.50 perplexity 541.79
eval: bucket 0 perplexity 1051.29
eval: bucket 1 perplexity 626.64
eval: bucket 2 perplexity 496.32
eval: bucket 3 perplexity 458.85
global step 180 learning rate 0.4950 step-time 16.69 perplexity 400.65
eval: bucket 0 perplexity 178.12
eval: bucket 1 perplexity 299.86
eval: bucket 2 perplexity 294.84
eval: bucket 3 perplexity 296.46
global step 190 learning rate 0.4950 step-time 19.93 perplexity 886.73
eval: bucket 0 perplexity 860.60
eval: bucket 1 perplexity 910.16
eval: bucket 2 perplexity 909.24
eval: bucket 3 perplexity 786.04
global step 200 learning rate 0.4901 step-time 18.75 perplexity 449.64
eval: bucket 0 perplexity 152.13
eval: bucket 1 perplexity 234.41
eval: bucket 2 perplexity 249.66
eval: bucket 3 perplexity 285.95
...
global step 980 learning rate 0.4215 step-time 18.31 perplexity 208.74
eval: bucket 0 perplexity 78.45
eval: bucket 1 perplexity 108.40
eval: bucket 2 perplexity 137.83
eval: bucket 3 perplexity 173.53
global step 990 learning rate 0.4173 step-time 17.31 perplexity 175.05
eval: bucket 0 perplexity 78.37
eval: bucket 1 perplexity 119.72
eval: bucket 2 perplexity 169.11
eval: bucket 3 perplexity 202.89
global step 1000 learning rate 0.4173 step-time 15.85 perplexity 174.33
eval: bucket 0 perplexity 76.52
eval: bucket 1 perplexity 125.97
eval: bucket 2 perplexity 150.13
eval: bucket 3 perplexity 181.07
...
经过350000轮训练模型之后,您可以将代码中的 main_train() 换为 main_decode() 来使用训练好的翻译器,
您输入一个英文句子,程序将输出一个对应的法文句子。
Reading model parameters from wmt/translate.ckpt-350000
> Who is the president of the United States?
Qui est le président des États-Unis ?
理解机器翻译
Seq2seq
序列到序列模型(Seq2seq)通常被用来转换一种语言到另一种语言。 但实际上它能用来做很多您可能无法想象的事情,比如我们可以将一个长的句子翻译成意思一样但短且简单的句子, 再比如,从莎士比亚的语言翻译成现代英语。若用上卷积神经网络(CNN)的话,我们能将视频翻译成句子,则自动看一段视频给出该视频的文字描述(Video captioning)。
如果你只是想用 Seq2seq,你只需要考虑训练集的格式,比如如何切分单词、如何数字化单词等等。 所以,在本教程中,我们将讨论很多如何整理训练集。
基础
序列到序列模型是一种多对多(Many to many)的模型,但与PTB教程中的同步序列输入与输出(Synced sequence input and output)不一样,Seq2seq是在输入了整个序列之后,才开始输出新的序列(非同步)。 该教程用了下列两种最新的方法来提高准确度:
- 把输入序列倒转输入(Reversing the inputs)
- 注意机制(Attention mechanism)
为了要加快训练速度,我们使用了:
- softmax 抽样(Sampled softmax)
Karpathy的博客是这样描述Seq2seq的:“(4) Sequence input and sequence output (e.g. Machine Translation: an RNN reads a sentence in English and then outputs a sentence in French).”

如上图所示,编码器输入(encoder input),解码器输入(decoder input)以及输出目标(targets)如下:
encoder_input = A B C
decoder_input = <go> W X Y Z
targets = W X Y Z <eos>
Note:在代码实现中,targets的长度比decoder_input的长度小一,更多实现细节将在下文说明。
文献
该英语-法语的机器翻译例子使用了多层递归神经网络以及注意机制。 该模型和如下论文中一样:
该例子采用了 softmax 抽样(sampled softmax)来解决当词汇表很大时计算量大的问题。
在该例子中,target_vocab_size=4000 ,若词汇量小于 512 时用普通的softmax cross entropy即可。
Softmax 抽样在这篇论文的第三小节中描述:
如下文章讲述了把输入序列倒转(Reversing the inputs)和多层神递归神经网络用在Seq2seq的翻译应用非常成功:
如下文章讲述了注意机制(Attention Mechanism)让解码器可以更直接地得到每一个输入的信息:
如下文章讲述了另一种Seq2seq模型,则使用双向编码器(Bi-directional encoder):
实现细节
Bucketing and Padding
Bucketing 是一种能有效处理不同句子长度的方法,为什么使用Bucketing,在 知乎上已经有很好的回答了。
当将英文翻译成法文的时,我们有不同长度的英文句子输入(长度为 L1 ),以及不同长度的法文句子输出,(长度为 L2 )。
我们原则上要建立每一种长度的可能性,则有很多个 (L1, L2+1) ,其中 L2 加一是因为有 GO 标志符。
为了减少 bucket 的数量以及为句子找到最合适的 bucket,若 bucket 大于句子的长度,我们则使用 PAD 标志符填充之。
为了提高效率,我们只使用几个 bucket,然后使用 padding 来让句子匹配到最相近的 bucket 中。 在该例子中,我们使用如下 4 个 buckets。
buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]
如果输入的是一个有 3 个单词的英文句子,对应的法文输出有 6 个单词,
那么改数据将被放在第一个 bucket 中并且把 encoder inputs 和 decoder inputs 通过 padding 来让其长度变成 5 和 10 。
如果我们有 8 个单词的英文句子,及 18 个单词的法文句子,它们会被放到 (20, 25) 的 bucket 中。
换句话说,bucket (I,O) 是 (encoder_input_size,decoder_inputs_size) 。
给出一对数字化训练样本 [["I", "go", "."], ["Je", "vais", "."]] ,我们把它转换为 (5,10) 。
编码器输入(encoder inputs)的训练数据为 [PAD PAD "." "go" "I"] ,而解码器的输入(decoder inputs)为 [GO "Je" "vais" "." EOS PAD PAD PAD PAD PAD] 。
而输出目标(targets)是解码器输入(decoder inputs)平移一位。 target_weights 是输出目标(targets)的掩码。
bucket = (I, O) = (5, 10)
encoder_inputs = [PAD PAD "." "go" "I"] <-- 5 x batch_size
decoder_inputs = [GO "Je" "vais" "." EOS PAD PAD PAD PAD PAD] <-- 10 x batch_size
target_weights = [1 1 1 1 0 0 0 0 0 0 0] <-- 10 x batch_size
targets = ["Je" "vais" "." EOS PAD PAD PAD PAD PAD] <-- 9 x batch_size
在该代码中,一个句子是由一个列向量表示,假设 batch_size = 3 , bucket = (5, 10) ,训练集如下所示。
encoder_inputs decoder_inputs target_weights targets
0 0 0 1 1 1 1 1 1 87 71 16748
0 0 0 87 71 16748 1 1 1 2 3 14195
0 0 0 2 3 14195 0 1 1 0 2 2
0 0 3233 0 2 2 0 0 0 0 0 0
3 698 4061 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0
0 0 0 0 0 0
其中 0 : _PAD 1 : _GO 2 : _EOS 3 : _UNK
在训练过程中,解码器输入是目标,而在预测过程中,下一个解码器的输入是最后一个解码器的输出。
在训练过程中,编码器输入(decoder inputs)就是目标输出(targets); 当使用模型时,下一个编码器输入(decoder inputs)是上一个解码器输出( decoder output)。
特殊标志符、标点符号与阿拉伯数字
该例子中的特殊标志符是:
= b
= b
= b
= b
= 0 <-- in
= 1
= 2
= 3
=
ID号 意义
_PAD 0 Padding, empty word
_GO 1 decoder_inputs 的第一个元素
_EOS 2 targets 的结束符
_UNK 3 不明单词(Unknown word),没有在词汇表出现的单词被标记为3
对于阿拉伯数字,建立词汇表时与数字化数据集时的 normalize_digits 必须是一致的,若
normalize_digits=True 所有阿拉伯数字都将被 0 代替。比如 123 被 000 代替,9 被 0代替
,1990-05 被 0000-00` 代替,最后 000,0,0000-00等将在词汇库中(看vocab40000.en`` )。
反之,如果 normalize_digits=False ,不同的阿拉伯数字将会放入词汇表中,那么词汇表就变得十分大了。
本例子中寻找阿拉伯数字使用的正则表达式是 _DIGIT_RE = re.compile(br"\d") 。(详见 tl.nlp.create_vocabulary() 和 ``tl.nlp.data_to_token_ids()` )
对于分离句子成独立单词,本例子使用正则表达式 _WORD_SPLIT = re.compile(b"([.,!?\"':;)(])") ,
这意味着使用这几个标点符号 [ . , ! ? " ' : ; ) ( ] 以及空格来分割句子,详情请看 tl.nlp.basic_tokenizer() 。这个分割方法是 tl.nlp.create_vocabulary() 和 tl.nlp.data_to_token_ids() 的默认方法。
所有的标点符号,比如 . , ) ( 在英文和法文数据库中都会被全部保留下来。
Softmax 抽样 (Sampled softmax)
softmax抽样是一种词汇表很大(Softmax 输出很多)的时候用来降低损失(cost)计算量的方法。
与从所有输出中计算 cross-entropy 相比,这个方法只从 num_samples 个输出中计算 cross-entropy。
损失和更新函数
EmbeddingAttentionSeq2seqWrapper 内部实现了 SGD optimizer。
下一步?
您可以尝试其他应用。
翻译对照
Stacked Denosing Autoencoder 堆栈式降噪自编码器
Word Embedding 词嵌套、词嵌入
Iteration 迭代
Natural Language Processing 自然语言处理
Sparse 稀疏的
Cost function 损失函数
Regularization 规则化、正则化
Tokenization 数字化
Truncated backpropagation 截断反向传播
更多信息
TensorLayer 还能做什么?请继续阅读本文档。
最后,API 参考列表和说明如下:
layers (tensorlayer.layers),
activation (tensorlayer.activation),
natural language processing (tensorlayer.nlp),
reinforcement learning (tensorlayer.rein),
cost expressions and regularizers (tensorlayer.cost),
load and save files (tensorlayer.files),
operating system (tensorlayer.ops),
helper functions (tensorlayer.utils),
visualization (tensorlayer.visualize),
iteration functions (tensorlayer.iterate),
preprocessing functions (tensorlayer.prepro),